
{kind=link}
[ad_1]
That is the primary put up in a collection by Rockset’s CTO Dhruba Borthakur on Designing the Subsequent Era of Knowledge Programs for Actual-Time Analytics. We’ll be publishing extra posts within the collection within the close to future, so subscribe to our weblog so you do not miss them!
Profitable data-driven firms like Uber, Fb and Amazon depend on real-time analytics. Personalizing buyer experiences for e-commerce, managing fleets and provide chains, and automating inner operations all require immediate insights on the freshest information.
To ship real-time analytics, firms want a contemporary know-how infrastructure that features these three issues:
- An actual-time information supply resembling net clickstreams, IoT occasions produced by sensors, and many others.
- A platform resembling Apache Kafka/Confluent, Spark or Amazon Kinesis for publishing that stream of occasion information.
- An actual-time analytics database able to constantly ingesting giant volumes of real-time occasions and returning question outcomes inside milliseconds.
Occasion streaming/stream processing has been round for nearly a decade. It’s effectively understood. Actual-time analytics is just not. One of many technical necessities for a real-time analytics database is mutability. Mutability is the superpower that allows updates, or mutations, to present information in your information retailer.
Variations Between Mutable and Immutable Knowledge
Earlier than we discuss why mutability is vital to real-time analytics, it’s necessary to grasp what it’s.
Mutable information is information saved in a desk document that may be erased or up to date with newer information. As an example, in a database of worker addresses, let’s say that every document has the title of the individual and their present residential tackle. The present tackle data could be overwritten if the worker strikes residences from one place to a different.
Historically, this data could be saved in transactional databases — Oracle Database, MySQL, PostgreSQL, and many others. — as a result of they permit for mutability: Any discipline saved in these transactional databases is updatable. For right now’s real-time analytics, there are a lot of further explanation why we want mutability, together with information enrichment and backfilling information.
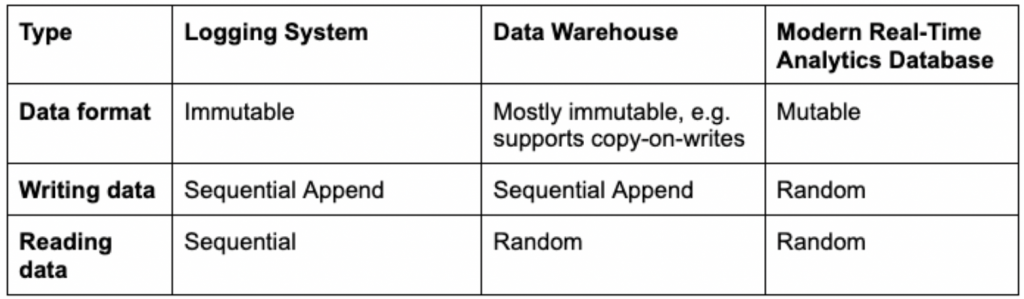
Immutable information is the alternative — it can’t be deleted or modified. Fairly than writing over present information, updates are append-only. Which means that updates are inserted into a distinct location otherwise you’re compelled to rewrite previous and new information to retailer it correctly. Extra on the downsides of this later. Immutable information shops have been helpful in sure analytics eventualities.
The Historic Usefulness of Immutability
Knowledge warehouses popularized immutability as a result of it eased scalability, particularly in a distributed system. Analytical queries might be accelerated by caching heavily-accessed read-only information in RAM or SSDs. If the cached information was mutable and doubtlessly altering, it must be constantly checked in opposition to the unique supply to keep away from turning into stale or faulty. This could have added to the operational complexity of the info warehouse; immutable information, however, created no such complications.
Immutability additionally reduces the danger of unintended information deletion, a major profit in sure use instances. Take well being care and affected person well being information. One thing like a brand new medical prescription could be added moderately than written over present or expired prescriptions so that you simply at all times have an entire medical historical past.
Extra lately, firms tried to pair stream publishing techniques resembling Kafka and Kinesis with immutable information warehouses for analytics. The occasion techniques captured IoT and net occasions and saved them as log information. These streaming log techniques are tough to question, so one would usually ship all the info from a log to an immutable information system resembling Apache Druid to carry out batch analytics.
The info warehouse would append newly-streamed occasions to present tables. Since previous occasions, in idea, don’t change, storing information immutably gave the impression to be the best technical choice. And whereas an immutable information warehouse may solely write information sequentially, it did help random information reads. That enabled analytical enterprise functions to effectively question information at any time when and wherever it was saved.
The Issues with Immutable Knowledge
In fact, customers quickly found that for a lot of causes, information does have to be up to date. That is very true for occasion streams as a result of a number of occasions can replicate the true state of a real-life object. Or community issues or software program crashes may cause information to be delivered late. Late-arriving occasions have to be reloaded or backfilled.
Firms additionally started to embrace information enrichment, the place related information is added to present tables. Lastly, firms began having to delete buyer information to satisfy client privateness laws resembling GDPR and its “proper to be forgotten.”
Immutable database makers have been compelled to create workarounds with a view to insert updates. One well-liked technique utilized by Apache Druid and others known as copy-on-write. Knowledge warehouses usually load information right into a staging space earlier than it’s ingested in batches into the info warehouse the place it’s saved, listed and made prepared for queries. If any occasions arrive late, the info warehouse must write the brand new information and rewrite already-written adjoining information with a view to retailer the whole lot accurately in the best order.
One other poor answer to cope with updates in an immutable information system is to maintain the unique information in Partition A (above) and write late-arriving information to a distinct location, Partition B. The appliance, and never the info system, must maintain observe of the place all linked-but-scattered information are saved, in addition to any ensuing dependencies. This course of known as referential integrity and needs to be carried out by the appliance software program.

Each workarounds have important issues. Copy-on-write requires information warehouses to expend a major quantity of processing energy and time — tolerable when updates are few, however intolerably expensive and gradual because the variety of updates rise. That creates important information latency that may rule out real-time analytics. Knowledge engineers should additionally manually supervise copy-on-writes to make sure all of the previous and new information is written and listed precisely.
An utility implementing referential integrity has its personal points. Queries should be double-checked that they’re pulling information from the best areas or run the danger of information errors. Trying any question optimizations, resembling caching information, additionally turns into far more difficult when updates to the identical document are scattered in a number of locations within the information system. Whereas these could have been tolerable at slower-paced batch analytic techniques, they’re enormous issues in relation to mission-critical real-time analytics.
Mutability Aids Machine Studying
At Fb, we constructed an ML mannequin that scanned all-new calendar occasions as they have been created and saved them within the occasion database. Then, in real-time, an ML algorithm would examine this occasion, and resolve whether or not it’s spam. Whether it is categorized as spam, then the ML mannequin code would insert a brand new discipline into that present occasion document to mark it as spam. As a result of so many occasions have been flagged and instantly taken down, the info needed to be mutable for effectivity and pace. Many fashionable ML-serving techniques have emulated our instance and chosen mutable databases.
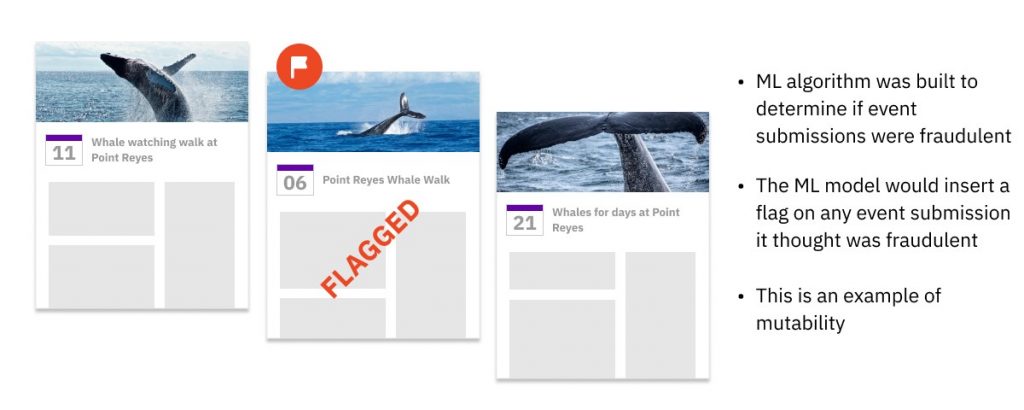
This degree of efficiency would have been unattainable with immutable information. A database utilizing copy-on-write would shortly get slowed down by the variety of flagged occasions it must replace. If the database saved the unique occasions in Partition A and appended flagged occasions to Partition B, this is able to require further question logic and processing energy, as each question must merge related information from each partitions. Each workarounds would have created an insupportable delay for our Fb customers, heightened the danger of information errors and created extra work for builders and/or information engineers.
How Mutability Permits Actual-Time Analytics
At Fb, I helped design mutable analytics techniques that delivered real-time pace, effectivity and reliability.
One of many applied sciences I based was open supply RocksDB, the high-performance key-value engine utilized by MySQL, Apache Kafka and CockroachDB. RocksDB’s information format is a mutable information format, which suggests you can replace, overwrite or delete particular person fields in a document. It’s additionally the embedded storage engine at Rockset, a real-time analytics database I based with absolutely mutable indexes.
By tuning open supply RocksDB, it’s attainable to allow SQL queries on occasions and updates arriving mere seconds earlier than. These queries may be returned within the low lots of of milliseconds, even when advanced, advert hoc and excessive concurrency. RocksDB’s compaction algorithms additionally mechanically merge previous and up to date information information to make sure that queries entry the most recent, appropriate model, in addition to stop information bloat that might hamper storage effectivity and question speeds.
By selecting RocksDB, you’ll be able to keep away from the clumsy, costly and error-creating workarounds of immutable information warehouses resembling copy-on-writes and scattering updates throughout completely different partitions.
To sum up, mutability is vital for right now’s real-time analytics as a result of occasion streams may be incomplete or out of order. When that occurs, a database might want to appropriate and backfill lacking and faulty information. To make sure excessive efficiency, low price, error-free queries and developer effectivity, your database should help mutability.
If you wish to see the entire key necessities of real-time analytics databases, watch my latest speak on the Hive on Designing the Subsequent Era of Knowledge Programs for Actual-Time Analytics, accessible beneath.
Embedded content material: https://www.youtube.com/watch?v=NOuxW_SXj5M
Rockset is the real-time analytics database within the cloud for contemporary information groups. Get quicker analytics on more energizing information, at decrease prices, by exploiting indexing over brute-force scanning.
[ad_2]