
On this second a part of our collection on Python textual content processing, builders will proceed studying find out how to scrape textual content, constructing upon the knowledge in our earlier article, Python: Extracting Textual content from Unfriendly File Codecs. You probably have but to take action, we encourage you to take a second to learn half one, because it serves as a constructing block for this Python programming tutorial. On this half, we are going to study the code we are able to use to start extracting textual content from recordsdata.
Parsing Textual content from Information with Python
Most programming languages course of textual content enter recordsdata through the use of an iterative – or looping – line-by-line methodology. Within the instance right here, all the info associated to a single document might be discovered inside the 4 strains that usually comprise every document, with the change from one SSN to a different delimiting a person document. Which means we want a loop that can seize all the info within the desk in our earlier article earlier than the loop finds a brand new SSN. We additionally have to maintain observe of the earlier document’s values in order that we all know when now we have discovered a brand new document. The simplest option to begin is to write down a primary Python script that may acknowledge when a brand new SSN begins. The Python code instance under exhibits find out how to parse out the SSN for every document:
Extractor.py
# Extractor.py
# For command-line arguments
import sys
def important(argv):
strive:
# Is there one command line param and is it a file?
if len(sys.argv) < 2:
increase IndexError("There should be a filename specified.")
with open(sys.argv[1]) as input_file:
# Create variables to carry every output document's info,
# together with corresponding values to carry the earlier document's
# info.
currentSSN = ""
previousSSN = ""
# Deal with the file as an enumerable object, cut up by newlines
for x, line in enumerate(input_file):
# Strip newlines from proper (trailing newlines)
currentLine = line.rstrip()
# For this instance, a single document consists of 4 strains.
# We'd like to ensure we get each bit of knowledge
# earlier than we transfer on to the subsequent document.
# Python strings are 0-indexed, so the thirteenth character is
# at place 12, and we should add the size of 11 to 12
# to get place 23 to finish the substring perform.
currentSSN = currentLine[12:23]
#print("Present SSN is ["+currentSSN+"]")
if (previousSSN != currentSSN):
# We're at a brand new document, and hopefully the finished
# document's info is saved within the "earlier"
# variations of all these variables. Observe that on the
# first iteration of this loop, the earlier variations
# of those variables will all be clean.
if ("" != previousSSN):
print ("Discovered document with SSN ["+previousSSN+"]")
# Reset for the subsequent document.
previousSSN = currentSSN
# Observe that on the finish of the loop, the final document's info
# might be within the earlier variations of the variables. We have to
# manually run this logic to get them.
if ("" != previousSSN):
print ("Final document with SSN ["+previousSSN+"]")
#print(str(x+1)+" strains learn.")
return 0
besides IndexError as ex:
print(str(ex))
besides FileNotFoundError as ex:
print("The file ["+ sys.argv[1] + "] can't be learn.")
return 1
# Name the "important" program.
if __name__ == "__main__":
important(sys.argv[1:])
The pattern information file is within the itemizing under:
42594 001-00-0837 Z000019 UZ3 5H2K 000000006518G 2022
001-00-0837 HPZ000000000000000000000000082725
2022 87 001-00-0837 NMR SMITH,ADAM
001-00-0837 VBPYT8923FZ00000000000000000
42594 020-01-0000 Z000019 UZ3 5H2K 000000011025Q 2022
020-01-0000 HPZ000000000000000000000000091442
2022 87 020-01-0000 NMR WILLIAMS,JAMES
020-01-0000 VBPYT8923FZ00000000000000000
020-33-0000 HPZ000000000000000000000000000000
020-33-0000 SW A00000000000000000
42594 200-00-0111 Z000019 UZ3 5H2K 000000003717H 2022
200-00-0111 HPZ000000000000000000000000061551
2022 87 200-00-0111 NMR MARLEY,RICHARD
200-00-0111 VBPYT8923FZ00000000000000000
42594 817-22-0000 Z000019 UZ3 5H2K 000000004235G 2022
817-22-0000 HPZ000000000000000000000000033258
2022 33 817-22-0000 NMR DOUGH,JOHN
817-22-0000 VBPYT8923FZ00000000000000000
42594 300-00-0001 Z000019 UZ3 5H2K 000000003096H 2022
300-00-0001 HPZ000000000000000000000000066889
2022 87 300-00-0001 NMR WILLIST,DOUGLAS
300-00-0001 VBPYT8923FZ00000000000000000
The above is the Pattern Information file, saved as Pattern Information.txt
Observe: Python makes use of 0-based indexing for strings, and the substring notation makes use of the ending place within the file as its finish, not the size of the substring. Due to this, the beginning of the SSN is represented by one quantity under its place to begin when discovered within the textual content editor.
For the ending place, the string size of 11 must be added to the 0-based index place of the string begin. As 12 is the 0-based index of the string begin, 23 is the 0-based index of the string finish.
In the event you run this code in Home windows, you’re going to get the next output:

Observe additionally that, on this instance, the total path to the Python interpreter is specified. Relying in your setup, you could not must be so specific. Nonetheless, on some methods, each Python 2 and Python 3 could also be put in, and the “default” Python interpreter that runs when a path will not be specified will not be the right one. Additionally it is assumed that the Pattern Information.txt file is in the identical listing because the Extractor.py file. As a result of this file has an area within the title, it should be encapsulated in citation marks to be acknowledged as a single parameter. This is applicable to each Home windows and Linux methods.
Earlier than going any additional, make sure that all the SSNs from the pattern file are displayed within the output. A typical mistake in these implementations is to disregard the handbook processing of the final document.
Learn: High On-line Programs to Study Python
Extracting Textual content from Information with Python
Now that the SSN is correctly parsed out, the remaining objects might be extracted by including appropriate logic:
Full-Extractor.py
# Full-Extractor.py
# For command-line arguments
import sys
def important(argv):
strive:
# Is there one command line param and is it a file?
if len(sys.argv) < 2:
increase IndexError("There should be a filename specified.")
with open(sys.argv[1]) as input_file:
# Create variables to carry every output document's info,
# together with corresponding values to carry the earlier document's
# info.
currentSSN = ""
previousSSN = ""
currentName = ""
currentMonthlyAmount = ""
currentYearlyAmount = ""
# This time, we have to know if we're processing the primary document. If we do not maintain observe of this, the
# first document will course of incorrectly and every subsequent document might be fallacious.
firstRecord = True
# Deal with the file as an enumerable object, cut up by newlines
for x, line in enumerate(input_file):
# Strip newlines from proper (trailing newlines)
currentLine = line.rstrip()
# For this instance, a single document consists of 4 strains.
# We'd like to ensure we get each bit of knowledge
# earlier than we transfer on to the subsequent document.
# Python strings are 0-indexed, so the thirteenth character is
# at place 12, and we should add the size of 11 to 12
# to get place 23 to finish the substring perform.
currentSSN = currentLine[12:23]
if (True == firstRecord):
previousSSN = currentSSN
firstRecord = False
# For the primary document, previousSSN can be clean and currentSSN would have a price, and this situation can be true.
# We don't need this, so we want the logic above to set the values to be the identical for the primary document.
if (previousSSN != currentSSN):
# We're at a brand new document, and hopefully the finished
# document's info is saved within the "earlier"
# variations of all these variables. Observe that on the
# first iteration of this loop, the earlier variations
# of those variables will all be clean.
# Additionally observe the "Disconnect" between the earlier and present notation.
if ("" != previousSSN):
print ("Discovered document with SSN ["+previousSSN+"], title ["+currentName+"], month-to-month quantity [" + currentMonthlyAmount+
"] yearly quantity [" + currentYearlyAmount + "]")
# Reset for the subsequent document. This logic wants to return earlier than the remaining information extractions, or you'll have
# "off by one" errors.
previousSSN = currentSSN
# Clean out the "present" variations of the variables (besides the SSN!) so the situations above might be true once more.
currentName = ""
currentMonthlyAmount = ""
currentYearlyAmount = ""
# Get the title if we don't have already got it. This situation prevents us from overwriting the title. Observe that if the
# information was structured in a manner that there was a couple of piece of knowledge at this place within the file, you'll
# want further logic to find out what it's you might be parsing out. On this instance, the simplistic logic of checking if
# the primary character is current and {that a} comma is within the substring is the "check".
if ("" == currentName) and (False == (currentLine[33:].startswith(' '))) and (True == currentLine[33:].__contains__(',')):
# Additionally observe that the title can go to the tip of the road, so
# no ending place is included right here.
currentName = currentLine[33:]
# Observe the identical logic for extracting the opposite info. On this case, make sure that the string incorporates solely
# numeric values. Within the case of the month-to-month quantity, we solely need to course of strains that finish in "2022" as these are
# the one strains which comprise this info.
if ("" == currentMonthlyAmount) and (currentLine.endswith("2022")):
currentMonthlyAmount = currentLine[51:57]
if ("" == currentYearlyAmount) and currentLine[57:62].isdigit():
currentYearlyAmount = currentLine[57:62]
# Observe that on the finish of the loop, the final document's info
# might be within the earlier variations of the variables. We have to
# manually run this logic to get them.
if ("" != previousSSN):
print ("Final document with SSN ["+previousSSN+"], title [" + currentName +"], month-to-month quantity [" + currentMonthlyAmount+
"] yearly quantity [" + currentYearlyAmount + "]")
#print(str(x+1)+" strains learn.")
return 0
besides IndexError as ex:
print(str(ex))
besides FileNotFoundError as ex:
print("The file ["+ sys.argv[1] + "] can't be learn.")
return 1
# Name the "important" program.
if __name__ == "__main__":
important(sys.argv[1:])
The location of the logic that determines the document boundary, on this case going from one SSN to a different, is vital, as a result of the opposite information might be “off by one” if that logic stays on the backside of the loop. Additionally it is equally vital that, for the primary document, the earlier SSN “matches” the present one, particularly in order that this logic won’t be executed on the primary iteration.
Operating this code offers the next output:

Observe the highlighted document and the way it has no title or quantities related to it. This “error,” as a result of lacking information within the authentic textual content file, is rendering accurately. The extraction course of shouldn’t add or take away from the info. As an alternative, it ought to characterize the info precisely as-is from the unique supply, or at the very least point out that there’s some kind of error with the info. This manner, a person can look again on the authentic information supply within the ERP to determine why this info is lacking.
Learn: File Dealing with in Python
Exporting Information right into a CSV File with Python
Now that we are able to extract the info programmatically, it’s time to write it out to a pleasant format. On this case, it will likely be a easy CSV file. First, we want a CSV file to write down to, and, on this case, it will likely be the identical title because the enter file, with the extension modified to “.csv”. The complete code with the output to .CSV is under:
Full-Extractor-Export.py
# Full-Extractor-Export.py
# For command-line arguments
import sys
def important(argv):
strive:
# Is there one command line param and is it a file?
if len(sys.argv) < 2:
increase IndexError("There should be a filename specified.")
fileNameParts = sys.argv[1].cut up(".")
fileNameParts[-1] = "csv"
outputFileName = ".".be part of(fileNameParts)
outputLines = "";
with open(sys.argv[1]) as input_file:
# Create variables to carry every output document's info,
# together with corresponding values to carry the earlier document's
# info.
currentSSN = ""
previousSSN = ""
currentName = ""
currentMonthlyAmount = ""
currentYearlyAmount = ""
# This time, we have to know if we're processing the primary document. If we do not maintain observe of this, the
# first document will course of incorrectly and every subsequent document might be fallacious.
firstRecord = True
# Deal with the file as an enumerable object, cut up by newlines
for x, line in enumerate(input_file):
# Strip newlines from proper (trailing newlines)
currentLine = line.rstrip()
# For this instance, a single document consists of 4 strains.
# We'd like to ensure we get each bit of knowledge
# earlier than we transfer on to the subsequent document.
# Python strings are 0-indexed, so the thirteenth character is
# at place 12, and we should add the size of 11 to 12
# to get place 23 to finish the substring perform.
currentSSN = currentLine[12:23]
if (True == firstRecord):
previousSSN = currentSSN
firstRecord = False
# For the primary document, previousSSN can be clean and currentSSN would have a price, and this situation can be true.
# We don't need this, so we want the logic above to set the values to be the identical for the primary document.
if (previousSSN != currentSSN):
# We're at a brand new document, and hopefully the finished
# document's info is saved within the "earlier"
# variations of all these variables. Observe that on the
# first iteration of this loop, the earlier variations
# of those variables will all be clean.
# Additionally observe the "Disconnect" between the earlier and present notation.
if ("" != previousSSN):
print ("Discovered document with SSN ["+previousSSN+"], title ["+currentName+"], month-to-month quantity [" + currentMonthlyAmount+
"] yearly quantity [" + currentYearlyAmount + "]")
# As a result of CSV is a trivially format to write down to, string processing can be utilized. Observe that we additionally want to separate
# the title into the primary and final names.
nameParts = currentName.cut up(",")
# That is trivial error checking. Ideally a extra sturdy error response system must be right here.
firstName = "Error"
lastName = "Error"
if (2 == len(nameParts)):
firstName = nameParts[1]
lastName = nameParts[0]
# Ought to there be any citation marks in these strings, they must be escaped within the CSV file through the use of
# double citation marks. Strings in CSV recordsdata ought to all the time be delimited with citation marks.
outputLines += (""" + previousSSN.substitute(""", """") + "","" + lastName.substitute(""", """") + "","" +
firstName.substitute(""", """") + "","" + currentMonthlyAmount.substitute(""", """") + "","" +
currentYearlyAmount.substitute(""", """") +""rn")
# Reset for the subsequent document. This logic wants to return earlier than the remaining information extractions, or you'll have
# "off by one" errors.
previousSSN = currentSSN
# Clean out the "present" variations of the variables (besides the SSN!) so the situations above might be true once more.
currentName = ""
currentMonthlyAmount = ""
currentYearlyAmount = ""
# Get the title if we don't have already got it. This situation prevents us from overwriting the title. Observe that if the
# information was structured in a manner that there was a couple of piece of knowledge at this place within the file, you'll
# want further logic to find out what it's you might be parsing out. On this instance, the simplistic logic of checking if
# the primary character is current and {that a} comma is within the substring is the "check".
if ("" == currentName) and (False == (currentLine[33:].startswith(' '))) and (True == currentLine[33:].__contains__(',')):
# Additionally observe that the title can go to the tip of the road, so
# no ending place is included right here.
currentName = currentLine[33:]
# Observe the identical logic for extracting the opposite info. On this case, make sure that the string incorporates solely
# numeric values. Within the case of the month-to-month quantity, we solely need to course of strains that finish in "2022" as these are
# the one strains which comprise this info.
if ("" == currentMonthlyAmount) and (currentLine.endswith("2022")):
currentMonthlyAmount = currentLine[51:57]
if ("" == currentYearlyAmount) and currentLine[57:62].isdigit():
currentYearlyAmount = currentLine[57:62]
# Observe that on the finish of the loop, the final document's info
# might be within the earlier variations of the variables. We have to
# manually run this logic to get them.
if ("" != previousSSN):
print ("Final document with SSN ["+previousSSN+"], title [" + currentName +"], month-to-month quantity [" + currentMonthlyAmount+
"] yearly quantity [" + currentYearlyAmount + "]")
nameParts = currentName.cut up(",")
firstName = "Error"
lastName = "Error"
if (2 == len(nameParts)):
firstName = nameParts[1]
lastName = nameParts[0§6]
outputLines += (""" + previousSSN.substitute(""", """") + "","" + lastName.substitute(""", """") + "","" +
firstName.substitute(""", """") + "","" + currentMonthlyAmount.substitute(""", """") + "","" +
currentYearlyAmount.substitute(""", """") +""rn")
# Because the string already incorporates newlines, make sure that to clean these out.
outputFile = open(outputFileName, "w", newline="")
outputFile.write(outputLines)
outputFile.shut()
print ("Wrote to [" + outputFileName + "]")
#print(str(x+1)+" strains learn.")
return 0
besides IndexError as ex:
print(str(ex))
besides FileNotFoundError as ex:
print("The file ["+ sys.argv[1] + "] can't be learn.")
return 1
# Name the "important" program.
if __name__ == "__main__":
important(sys.argv[1:])
For optimum compatibility, all information parts in a CSV file must be encapsulated with citation marks, with any citation marks inside these strings being escaped with double citation marks. The above code displays this.
Operating the code offers this output:
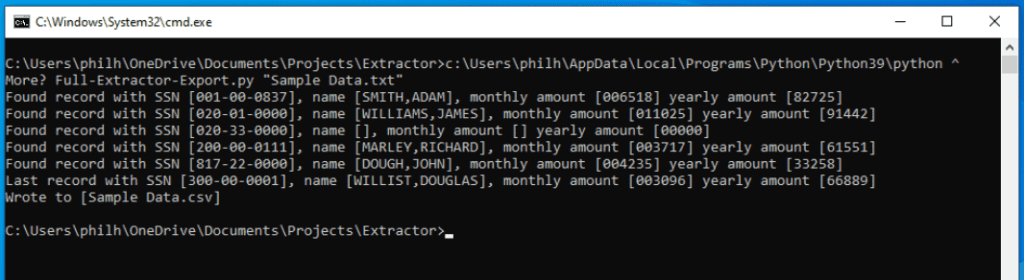
The above command makes use of the caret (^) conference to separate the command between strains for higher readability. The command might be a single line in case you selected.
The output as displayed in Notepad++:
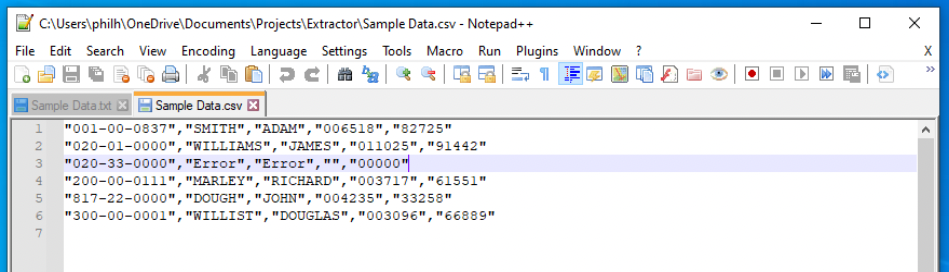
In fact, the entire level of this train is to see the output in Excel, so now let’s open this file there:
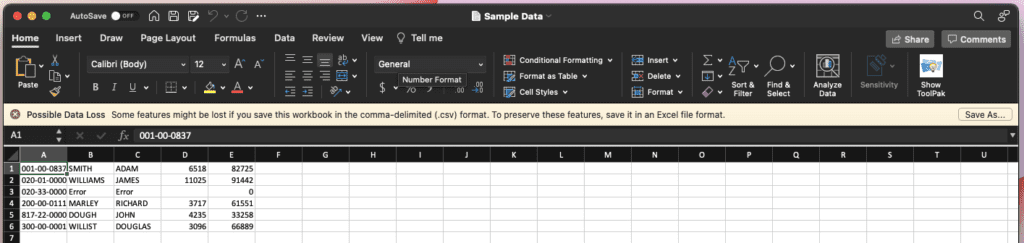
Now that the info is in Excel, all the instruments that the answer brings to the desk can now be utilized to this information. Any sorts of errors which will have been current within the ERP-generated information can now be correctly troubleshot and corrected in the identical manner, with out having to fret about sending dangerous information out earlier than it may be verified.
Observe that the “Error” values within the cells above are intentional, as they’re the results of the unique information being clean. From a excessive degree, this may assist to indicate a reviewer in a short time that there’s a drawback.
One other manner this might be accomplished is to write down out a extra informative error message right into a neighboring cell in the identical row.
Learn: How you can Type Lists in Python
Ultimate Ideas on Textual content Scraping in Python
The fantastic thing about this resolution is that, whereas the code seems to be complicated, particularly in comparison with an much more complicated common expression, it may be extra readily reused and tailored for equally structured recordsdata. This type of resolution can change into an indispensable device within the arsenal of somebody who’s tasked with verifying this sort of info from a “black field” information supply like an ERP, or past.
Learn extra Python programming tutorials and developer guides.


{kind=link}