
{kind=link}
[ad_1]
Snowflake’s knowledge cloud permits firms to retailer and share knowledge, then analyze this knowledge for enterprise intelligence. Though Snowflake is a good software, generally querying huge quantities of knowledge runs slower than your functions — and customers — require.
In our first article, What Do I Do When My Snowflake Question Is Sluggish? Half 1: Prognosis, we mentioned methods to diagnose gradual Snowflake question efficiency. Now it’s time to handle these points.
We’ll cowl Snowflake efficiency tuning, together with lowering queuing, utilizing outcome caching, tackling disk spilling, rectifying row explosion, and fixing insufficient pruning. We’ll additionally talk about options for real-time analytics that could be what you’re in search of in case you are in want of higher real-time question efficiency.
Scale back Queuing
Snowflake strains up queries till sources can be found. It’s not good for queries to remain queued too lengthy, as they are going to be aborted. To forestall queries from ready too lengthy, you have got two choices: set a timeout or alter concurrency.
Set a Timeout
Use STATEMENT_QUEUED_TIMEOUT_IN_SECONDS to outline how lengthy your question ought to keep queued earlier than aborting. With a default worth of 0, there isn’t any timeout.
Change this quantity to abort queries after a selected time to keep away from too many queries queuing up. As this can be a session-level question, you possibly can set this timeout for specific periods.
Modify the Most Concurrency Stage
The full load time depends upon the variety of queries your warehouse executes in parallel. The extra queries that run in parallel, the tougher it’s for the warehouse to maintain up, impacting Snowflake efficiency.
To rectify this, use Snowflake’s MAX_CONCURRENCY_LEVEL parameter. Its default worth is 8, however you possibly can set the worth to the variety of sources you wish to allocate.
Conserving the MAX_CONCURRENCY_LEVEL low helps enhance execution velocity, even for advanced queries, as Snowflake allocates extra sources.
Use Outcome Caching
Each time you execute a question, it caches, so Snowflake doesn’t must spend time retrieving the identical outcomes from cloud storage sooner or later.
One solution to retrieve outcomes immediately from the cache is by RESULT_SCAN.
Fox instance:
choose * from desk(result_scan(last_query_id()))
The LAST_QUERY_ID is the beforehand executed question. RESULT_SCAN brings the outcomes immediately from the cache.
Sort out Disk Spilling
When knowledge spills to your native machine, your operations should use a small warehouse. Spilling to distant storage is even slower.
To deal with this problem, transfer to a extra in depth warehouse with sufficient reminiscence for code execution.
alter warehouse mywarehouse
warehouse_size = XXLARGE
auto_suspend = 300
auto_resume = TRUE;
This code snippet allows you to scale up your warehouse and droop question execution mechanically after 300 seconds. If one other question is in line for execution, this warehouse resumes mechanically after resizing is full.
Prohibit the outcome show knowledge. Select the columns you wish to show and keep away from the columns you don’t want.
choose last_name
from employee_table
the place employee_id = 101;
choose first_name, last_name, country_code, telephone_number, user_id from
employee_table
the place employee_type like "%junior%";
The primary question above is particular because it retrieves the final identify of a selected worker. The second question retrieves all of the rows for the employee_type of junior, with a number of different columns.
Rectify Row Explosion
Row explosion occurs when a JOIN question retrieves many extra rows than anticipated. This could happen when your be part of by chance creates a cartesian product of all rows retrieved from all tables in your question.
Use the Distinct Clause
One solution to scale back row explosion is by utilizing the DISTINCT clause that neglects duplicates.
For instance:
SELECT DISTINCT a.FirstName, a.LastName, v.District
FROM information a
INNER JOIN sources v
ON a.LastName = v.LastName
ORDER BY a.FirstName;
On this snippet, Snowflake solely retrieves the distinct values that fulfill the situation.
Use Momentary Tables
Another choice to scale back row explosion is by utilizing momentary tables.
This instance exhibits methods to create a short lived desk for an present desk:
CREATE TEMPORARY TABLE tempList AS
SELECT a,b,c,d FROM table1
INNER JOIN table2 USING (c);
SELECT a,b FROM tempList
INNER JOIN table3 USING (d);
Momentary tables exist till the session ends. After that, the person can not retrieve the outcomes.
Examine Your Be part of Order
Another choice to repair row explosion is by checking your be part of order. Inside joins might not be a problem, however the desk entry order impacts the output for outer joins.
Snippet one:
orders LEFT JOIN merchandise
ON merchandise.id = merchandise.id
LEFT JOIN entries
ON entries.id = orders.id
AND entries.id = merchandise.id
Snippet two:
orders LEFT JOIN entries
ON entries.id = orders.id
LEFT JOIN merchandise
ON merchandise.id = orders.id
AND merchandise.id = entries.id
In principle, outer joins are neither associative nor commutative. Thus, snippet one and snippet two don’t return the identical outcomes. Pay attention to the be part of sort you utilize and their order to avoid wasting time, retrieve the anticipated outcomes, and keep away from row explosion points.
Repair Insufficient Pruning
Whereas operating a question, Snowflake prunes micro-partitions, then the remaining partitions’ columns. This makes scanning straightforward as a result of Snowflake now doesn’t should undergo all of the partitions.
Nevertheless, pruning doesn’t occur completely on a regular basis. Right here is an instance:
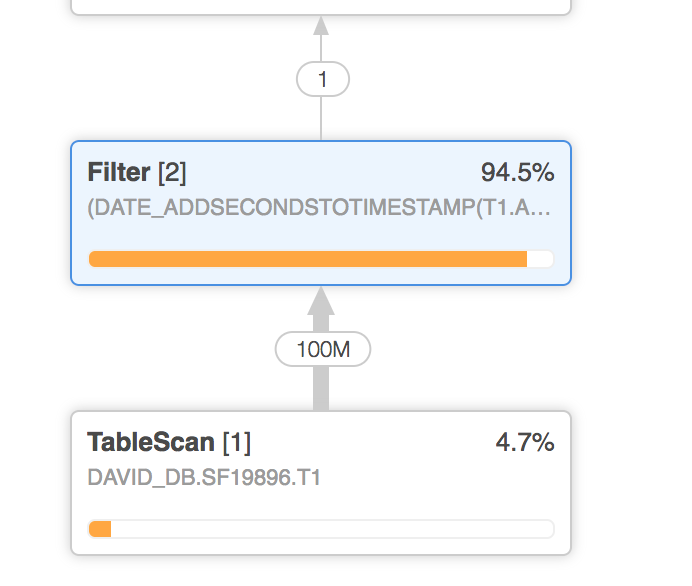
When executing the question, the filter removes about 94 % of the rows. Snowflake prunes the remaining partitions. Meaning the question scanned solely a portion of the 4 % of the rows retrieved.
Knowledge clustering can considerably enhance this. You possibly can cluster a desk while you create it or while you alter an present desk.
CREATE TABLE recordsTable (C1 INT, C2 INT) CLUSTER BY (C1, C2);
ALTER TABLE recordsTable CLUSTER BY (C1, C2);
Knowledge clustering has limitations. Tables will need to have a lot of information and shouldn’t change regularly. The best time to cluster is when the question is gradual, and you could improve it.
In 2020, Snowflake deprecated the guide re-clustering characteristic, so that isn’t an possibility anymore.
Wrapping Up Snowflake Efficiency Points
We defined methods to use queuing parameters, effectively use Snowflake’s cache, and repair disk spilling and exploding rows. It’s straightforward to implement all these strategies to assist enhance your Snowflake question efficiency.
One other Technique for Bettering Question Efficiency: Indexing
Snowflake generally is a good answer for enterprise intelligence, but it surely’s not all the time the optimum alternative for each use case, for instance, scaling real-time analytics, which requires velocity. For that, think about supplementing Snowflake with a database like Rockset.
Excessive-performance real-time queries and low latency are Rockset’s core options. Rockset supplies lower than one second of knowledge latency on giant knowledge units, making new knowledge prepared to question rapidly. Rockset excels at knowledge indexing, which Snowflake doesn’t do, and it indexes all the fields, making it sooner to your utility to scan by way of and supply real-time analytics. Rockset is much extra compute-efficient than Snowflake, delivering queries which are each quick and economical.
Rockset is a wonderful complement to your Snowflake knowledge warehouse. Join to your free Rockset trial to see how we will help drive your real-time analytics.
Rockset is the real-time analytics database within the cloud for contemporary knowledge groups. Get sooner analytics on brisker knowledge, at decrease prices, by exploiting indexing over brute-force scanning.
[ad_2]