
[ad_1]
Amazon Redshift is essentially the most broadly used cloud information warehouse. Amazon Redshift makes it simple and cost-effective to carry out analytics on huge quantities of knowledge. Amazon Redshift launched Streaming Ingestion for Amazon Kinesis Information Streams, which allows you to load information into Amazon Redshift with low latency and with out having to stage the information in Amazon Easy Storage Service (Amazon S3). This new functionality allows you to construct reviews and dashboards and carry out analytics utilizing recent and present information, while not having to handle customized code that periodically hundreds new information.
Upsolver is an AWS Superior Know-how Accomplice that allows you to ingest information from a variety of sources, remodel it, and cargo the outcomes into your goal of selection, equivalent to Kinesis Information Streams and Amazon Redshift. Information analysts, engineers, and information scientists outline their transformation logic utilizing SQL, and Upsolver automates the deployment, scheduling, and upkeep of the information pipeline. It’s pipeline ops simplified!
There are a number of methods to stream information to Amazon Redshift and on this submit we are going to cowl two choices that Upsolver might help you with: First, we present you methods to configure Upsolver to stream occasions to Kinesis Information Streams which might be consumed by Amazon Redshift utilizing Streaming Ingestion. Second, we exhibit methods to write occasion information to your information lake and eat it utilizing Amazon Redshift Serverless so you’ll be able to go from uncooked occasions to analytics-ready datasets in minutes.
Stipulations
Earlier than you get began, it’s worthwhile to set up Upsolver. You’ll be able to join Upsolver and deploy it instantly into your VPC to securely entry Kinesis Information Streams and Amazon Redshift.
Configure Upsolver to stream occasions to Kinesis Information Streams
The next diagram represents the structure to put in writing occasions to Kinesis Information Streams and Amazon Redshift.

To implement this resolution, you full the next high-level steps:
- Configure the supply Kinesis information stream.
- Execute the information pipeline.
- Create an Amazon Redshift exterior schema and materialized view.
Configure the supply Kinesis information stream
For the aim of this submit, you create an Amazon S3 information supply that accommodates pattern retail information in JSON format. Upsolver ingests this information as a stream; as new objects arrive, they’re mechanically ingested and streamed to the vacation spot.
- On the Upsolver console, select Information Sources within the navigation sidebar.
- Select New.
- Select Amazon S3 as your information supply.
- For Bucket, you need to use the bucket with the general public dataset or a bucket with your individual information.
- Select Proceed to create the information supply.

- Create a knowledge stream in Kinesis Information Streams, as proven within the following screenshot.

That is the output stream Upsolver makes use of to put in writing occasions which might be consumed by Amazon Redshift.
Subsequent, you create a Kinesis connection in Upsolver. Making a connection allows you to outline the authentication methodology Upsolver makes use of—for instance, an AWS Id and Entry Administration (IAM) entry key and secret key or an IAM position.
- On the Upsolver console, select Extra within the navigation sidebar.
- Select Connections.
- Select New Connection.
- Select Amazon Kinesis.
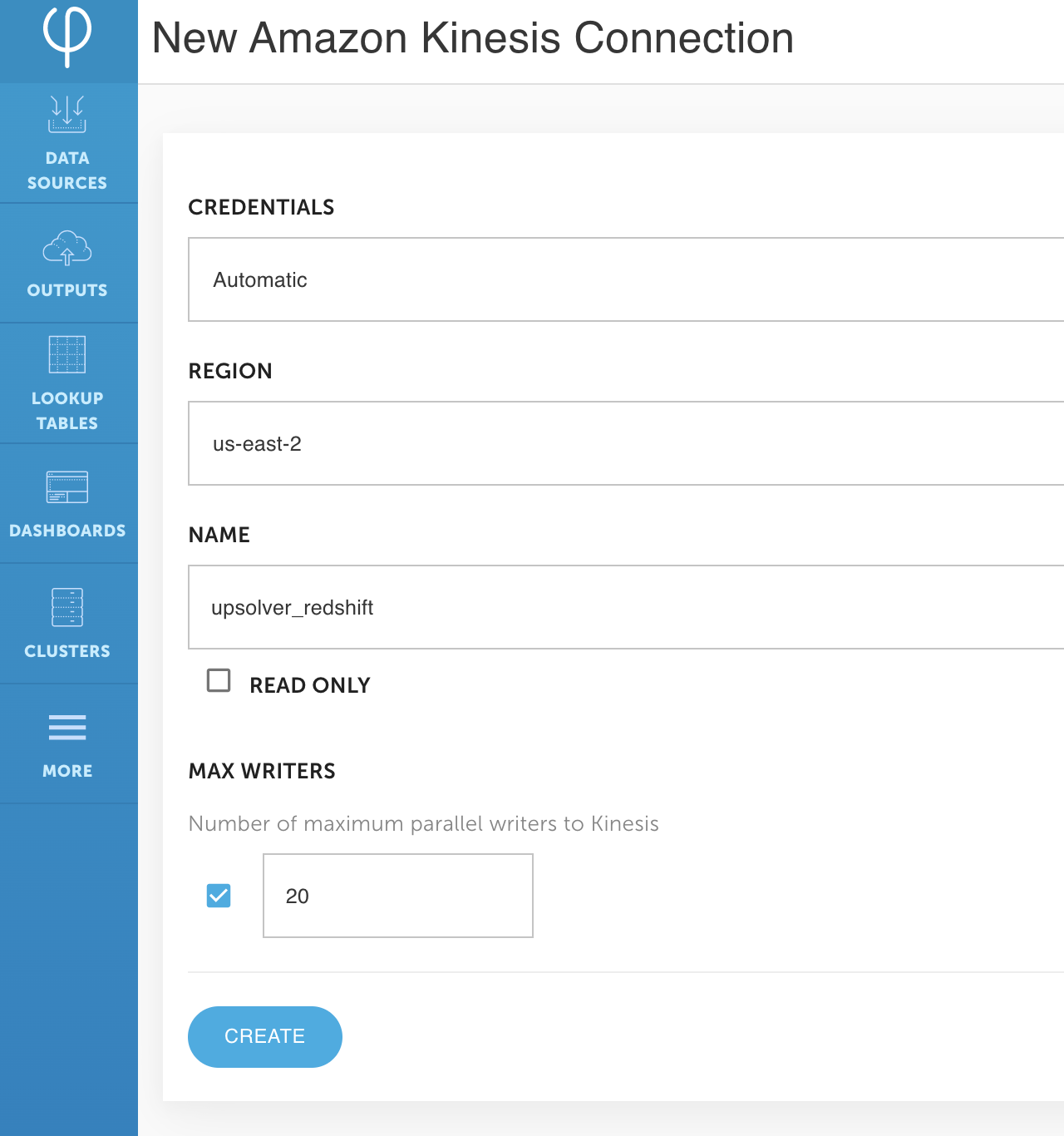
- For Area, enter your AWS Area.
- For Identify, enter a reputation in your connection (for this submit, we identify it
upsolver_redshift). - Select Create.

Earlier than you’ll be able to eat the occasions in Amazon Redshift, it’s essential to write them to the output Kinesis information stream.
- On the Upsolver console, navigate to Outputs and select Kinesis.
- For Information Sources, select the Kinesis information supply you created within the earlier step.
- Relying on the construction of your occasion information, you’ve got two selections:
- If the occasion information you’re writing to the output doesn’t include any nested fields, choose Tabular. Upsolver mechanically flattens nested information for you.
- To put in writing your information in a nested format, choose Hierarchical.
- As a result of we’re working with Kinesis Information Streams, choose Hierarchical.


Execute the information pipeline
Now that the stream is linked from the supply to an output, it’s essential to choose which fields of the supply occasion you want to cross by means of. You can too select to use transformations to your information—for instance, including right timestamps, masking delicate values, and including computed fields. For extra data, check with Fast information: SQL information transformation.
After including the columns you need to embrace within the output and making use of transformations, select Run to begin the information pipeline. As new occasions arrive within the supply, Upsolver mechanically transforms them and forwards the outcomes to the output stream. There isn’t any have to schedule or orchestrate the pipeline; it’s all the time on.

Create an Amazon Redshift exterior schema and materialized view
First, create an IAM position with the suitable permissions (for extra data, check with Streaming ingestion). Now you need to use the Amazon Redshift question editor, AWS Command Line Interface (AWS CLI), or API to run the next SQL statements.
- Create an exterior schema that’s backed by Kinesis Information Streams. The next command requires you to incorporate the IAM position you created earlier:
- Create a materialized view that permits you to run a SELECT assertion in opposition to the occasion information that Upsolver produces:
- Instruct Amazon Redshift to materialize the outcomes to a desk referred to as
mv_orders: - Now you can run queries in opposition to your streaming information, equivalent to the next:

Use Upsolver to put in writing information to a knowledge lake and question it with Amazon Redshift Serverless
The next diagram represents the structure to put in writing occasions to your information lake and question the information with Amazon Redshift.

To implement this resolution, you full the next high-level steps:
- Configure the supply Kinesis information stream.
- Connect with the AWS Glue Information Catalog and replace the metadata.
- Question the information lake.
Configure the supply Kinesis information stream
We already accomplished this step earlier within the submit, so that you don’t have to do something completely different.
Connect with the AWS Glue Information Catalog and replace the metadata
To replace the metadata, full the next steps:
- On the Upsolver console, select Extra within the navigation sidebar.
- Select Connections.
- Select the AWS Glue Information Catalog connection.
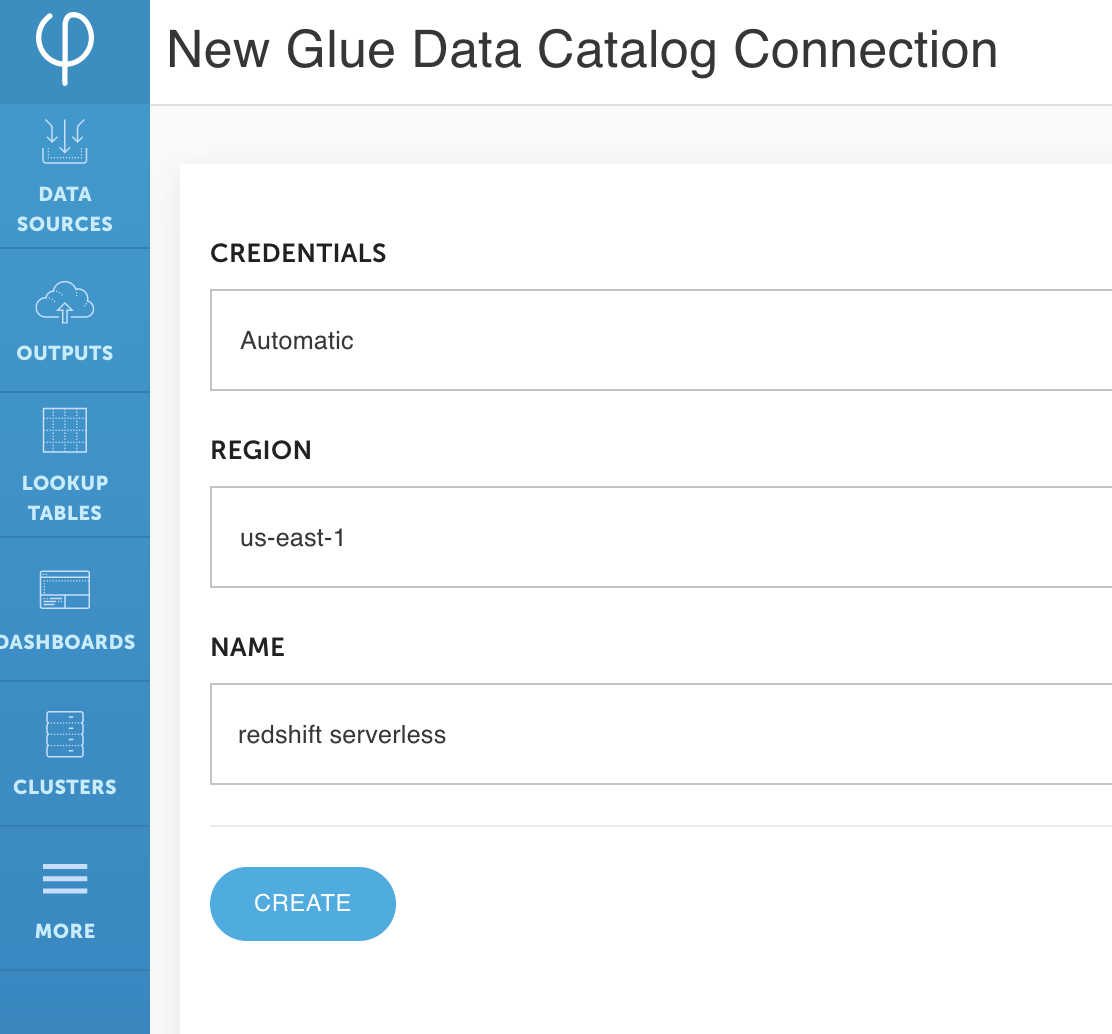
- For Area, enter your Area.
- For Identify, enter a reputation (for this submit, we name it
redshift serverless). - Select Create.

- Create a Redshift Spectrum output, following the identical steps from earlier on this submit.
- Choose Tabular as we’re writing output in table-formatted information to Amazon Redshift.

- Map the information supply fields to the Redshift Spectrum output.
- Select Run.

- On the Amazon Redshift console, create an Amazon Redshift Serverless endpoint.
- Be sure you affiliate your Upsolver position to Amazon Redshift Serverless.
- When the endpoint launches, open the brand new Amazon Redshift question editor to create an exterior schema that factors to the AWS Glue Information Catalog (see the next screenshot).


{kind=link}
This allows you to run queries in opposition to information saved in your information lake.

Question the information lake
Now that your Upsolver information is being mechanically written and maintained in your information lake, you’ll be able to question it utilizing your most popular device and the Amazon Redshift question editor, as proven within the following screenshot.

Conclusion
On this submit, you discovered methods to use Upsolver to stream occasion information into Amazon Redshift utilizing streaming ingestion for Kinesis Information Streams. You additionally discovered how you need to use Upsolver to put in writing the stream to your information lake and question it utilizing Amazon Redshift Serverless.
Upsolver makes it simple to construct information pipelines utilizing SQL and automates the complexity of pipeline administration, scaling, and upkeep. Upsolver and Amazon Redshift allow you to rapidly and simply analyze information in actual time.
When you’ve got any questions, or want to focus on this integration or discover different use circumstances, begin the dialog in our Upsolver Neighborhood Slack channel.
Concerning the Authors
 Roy Hasson is the Head of Product at Upsolver. He works with prospects globally to simplify how they construct, handle and deploy information pipelines to ship top quality information as a product. Beforehand, Roy was a Product Supervisor for AWS Glue and AWS Lake Formation.
Roy Hasson is the Head of Product at Upsolver. He works with prospects globally to simplify how they construct, handle and deploy information pipelines to ship top quality information as a product. Beforehand, Roy was a Product Supervisor for AWS Glue and AWS Lake Formation.
 Mei Lengthy is a Product Supervisor at Upsolver. She is on a mission to make information accessible, usable and manageable within the cloud. Beforehand, Mei performed an instrumental position working with the groups that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes tasks.
Mei Lengthy is a Product Supervisor at Upsolver. She is on a mission to make information accessible, usable and manageable within the cloud. Beforehand, Mei performed an instrumental position working with the groups that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes tasks.
 Maneesh Sharma is a Senior Database Engineer at AWS with greater than a decade of expertise designing and implementing large-scale information warehouse and analytics options. He collaborates with numerous Amazon Redshift Companions and prospects to drive higher integration.
Maneesh Sharma is a Senior Database Engineer at AWS with greater than a decade of expertise designing and implementing large-scale information warehouse and analytics options. He collaborates with numerous Amazon Redshift Companions and prospects to drive higher integration.
[ad_2]