
Apache Kafka is well-known for its efficiency and tunability to optimize for varied use circumstances. However generally it may be difficult to seek out the fitting infrastructure configuration that meets your particular efficiency necessities whereas minimizing the infrastructure value.
This publish explains how the underlying infrastructure impacts Apache Kafka efficiency. We talk about methods on how you can dimension your clusters to fulfill your throughput, availability, and latency necessities. Alongside the way in which, we reply questions like “when does it make sense to scale up vs. scale out?” We finish with steerage on how you can repeatedly confirm the dimensions of your manufacturing clusters.
We use efficiency assessments as an example and clarify the impact and trade-off of various methods to dimension your cluster. However as typical, it’s vital to not simply blindly belief benchmarks you occur to seek out on the web. We due to this fact not solely present how you can reproduce the outcomes, but in addition clarify how you can use a efficiency testing framework to run your personal assessments in your particular workload traits.
Sizing Apache Kafka clusters
The commonest useful resource bottlenecks for clusters from an infrastructure perspective are community throughput, storage throughput, and community throughput between brokers and the storage backend for brokers utilizing community hooked up storage corresponding to Amazon Elastic Block Retailer (Amazon EBS).
The rest of the publish explains how the sustained throughput restrict of a cluster not solely is dependent upon the storage and community throughput limits of the brokers, but in addition on the variety of brokers and shopper teams in addition to the replication issue r. We derive the next system (known as Equation 1 all through this publish) for the theoretical sustained throughput restrict tcluster given the infrastructure traits of a selected cluster:
For manufacturing clusters, it’s a greatest follow to focus on the precise throughput at 80% of its theoretical sustained throughput restrict. Contemplate, as an illustration, a three-node cluster with m5.12xlarge brokers, a replication issue of three, EBS volumes with a baseline throughput of 1000 MB/sec, and two shopper teams consuming from the tip of the subject. Taking all these parameters under consideration, the sustained throughput absorbed by the cluster ought to goal 800 MB/sec.
Nevertheless, this throughput calculation is merely offering an higher sure for workloads which might be optimized for top throughput situations. No matter the way you configure your matters and the shoppers studying from and writing into these matters, the cluster can’t take in extra throughput. For workloads with completely different traits, like latency-sensitive or compute-intensive workloads, the precise throughput that may be absorbed by a cluster whereas assembly these further necessities is commonly smaller.
To seek out the fitting configuration in your workload, it’s good to work backward out of your use case and decide the suitable throughput, availability, sturdiness, and latency necessities. Then, use Equation 1 to acquire the preliminary sizing of your cluster based mostly in your throughput, sturdiness, and storage necessities. Confirm this preliminary cluster sizing by working efficiency assessments after which fine-tune the cluster dimension, cluster configuration, and consumer configuration to fulfill your different necessities. Lastly, add further capability for manufacturing clusters to allow them to nonetheless ingest the anticipated throughput even when the cluster is working at lowered capability, as an illustration, throughout upkeep, scaling, or lack of a dealer. Relying in your workload, you could even take into account including sufficient spare capability to withstanding an occasion affecting all brokers of a complete Availability Zone.
The rest of the publish dives deeper into the features of cluster sizing. Crucial features are as follows:
- There may be usually a alternative between both scaling out or scaling as much as improve the throughput and efficiency of a cluster. Small brokers offer you smaller capability increments and have a smaller blast radius in case they develop into unavailable. However having many small brokers will increase the time it takes for operations that require a rolling replace to brokers to finish, and will increase the probability for failure.
- All site visitors that producers are sending right into a cluster is continued to disk. Due to this fact, the underlying throughput of the storage quantity can develop into the bottleneck of the cluster. On this case, it is smart to both improve the amount throughput if potential or so as to add extra volumes to the cluster.
- All information continued on EBS volumes traverses the community. Amazon EBS-optimized situations include devoted capability for Amazon EBS I/O, however the devoted Amazon EBS community can nonetheless develop into the bottleneck of the cluster. On this case, it is smart to scale up brokers, as a result of bigger brokers have larger Amazon EBS community throughput.
- The extra shopper teams which might be studying from the cluster, the extra information that egresses over the Amazon Elastic Compute Cloud (Amazon EC2) community of the brokers. Relying on the dealer kind and dimension, the Amazon EC2 community can develop into the bottleneck of the cluster. In that case, it is smart to scale up brokers, as a result of bigger brokers have larger Amazon EC2 community throughput.
- For p99 put latencies, there’s a substantial efficiency affect of enabling in-cluster encryption. Scaling up the brokers of a cluster can considerably scale back the p99 put latency in comparison with smaller brokers.
- When customers fall behind or must reprocess historic information, the requested information might now not reside in reminiscence, and brokers must fetch information from the storage quantity. This causes non-sequential I/O reads. When utilizing EBS volumes, it additionally causes further community site visitors to the amount. Utilizing bigger brokers with extra reminiscence or enabling compression can mitigate this impact.
- Utilizing the burst capabilities of your cluster is a really highly effective option to take in sudden throughput spikes with out scaling your cluster, which takes time to finish. Burst capability additionally helps in response to operational occasions. For example, when brokers are present process upkeep or partitions have to be rebalanced inside the cluster, they’ll use the burst efficiency to finish the operation sooner.
- Monitor or alarm on vital infrastructure-related cluster metrics corresponding to
BytesInPerSec,ReplicationBytesInPerSec,BytesOutPerSec, andReplicationBytesOutPerSecto obtain notification when the present cluster dimension is now not optimum for the present cluster dimension.
The rest of the publish gives further context and explains the reasoning behind these suggestions.
Understanding Apache Kafka efficiency bottlenecks
Earlier than we begin speaking about efficiency bottlenecks from an infrastructure perspective, let’s revisit how information flows inside a cluster.
For this publish, we assume that producers and customers are behaving properly and in keeping with greatest practices, except explicitly said otherwise. For instance, we assume the producers are evenly balancing the load between brokers, brokers host the identical variety of partitions, there are sufficient partitions to ingest the throughput, customers eat straight from the tip of the stream, and so forth. The brokers are receiving the identical load and are doing the identical work. We due to this fact simply deal with Dealer 1 within the following diagram of an information stream inside a cluster.

The producers ship an combination throughput of tcluster into the cluster. Because the site visitors evenly spreads throughout brokers, Dealer 1 receives an incoming throughput of tcluster/3. With a replication issue of 3, Dealer 1 replicates the site visitors it straight receives to the 2 different brokers (the blue traces). Likewise, Dealer 1 receives replication site visitors from two brokers (the purple traces). Every shopper group consumes the site visitors that’s straight produced into Dealer 1 (the inexperienced traces). All site visitors that arrives in Dealer 1 from producers and replication site visitors from different brokers is ultimately continued to storage volumes hooked up to the dealer.
Accordingly, the throughput of the storage quantity and the dealer community are each tightly coupled with the general cluster throughput and warrant a better look.
Storage backend throughput traits
Apache Kafka has been designed to make the most of massive sequential I/O operations when writing information to disk. Producers are solely ever appending information to the tip of the log, inflicting sequential writes. Furthermore, Apache Kafka is just not synchronously flushing to disk. As an alternative, Apache Kafka is writing to the web page cache, leaving it as much as the working system to flush pages to disk. This ends in massive sequential I/O operations, which optimizes disk throughput.
For a lot of sensible functions, the dealer can drive the total throughput of the amount and isn’t restricted by IOPS. We assume that buyers are studying from the tip of the subject. This suggests that efficiency of EBS volumes is throughput sure and never I/O sure, and reads are served from the web page cache.
The ingress throughput of the storage backend is dependent upon the information that producers are sending on to the dealer plus the replication site visitors the dealer is receiving from its friends. For an aggregated throughput produced into the cluster of tcluster and a replication issue of r, the throughput acquired by the dealer storage is as follows:
Due to this fact, the sustained throughput restrict of the whole cluster is sure by the next:
AWS provides completely different choices for block storage: occasion storage and Amazon EBS. Occasion storage is positioned on disks which might be bodily hooked up to the host pc, whereas Amazon EBS is community hooked up storage.
Occasion households that include occasion storage obtain excessive IOPS and disk throughput. For example, Amazon EC2 I3 situations embody NVMe SSD-based occasion storage optimized for low latency, very excessive random I/O efficiency, and excessive sequential learn throughput. Nevertheless, the volumes are tied to brokers. Their traits, particularly their dimension, solely depend upon the occasion household, and the amount dimension can’t be tailored. Furthermore, when a dealer fails and must be changed, the storage quantity is misplaced. The substitute dealer then wants to duplicate the information from different brokers. This replication causes further load on the cluster along with the lowered capability from the dealer loss.
In distinction, the traits of EBS volumes could be tailored whereas they’re in use. You should use these capabilities to routinely scale dealer storage over time fairly than provisioning storage for peak or including further brokers. Some EBS quantity sorts, corresponding to gp3, io2, and st1, additionally permit you to adapt the throughput and IOPS traits of current volumes. Furthermore, the lifecycle of EBS volumes is impartial of the dealer—if a dealer fails and must be changed, the EBS quantity could be reattached to the substitute dealer. This avoids many of the in any other case required replication site visitors.
Utilizing EBS volumes is due to this fact usually a good selection for a lot of frequent Apache Kafka workloads. They supply extra flexibility and allow sooner scaling and restoration operations.
Amazon EBS throughput traits
When utilizing Amazon EBS because the storage backend, there are a number of quantity sorts to select from. The throughput traits of the completely different quantity sorts vary between 128 MB/sec and 4000 MB/sec (for extra info, consult with Amazon EBS quantity sorts). You’ll be able to even select to connect a number of volumes to a dealer to extend the throughput past what could be delivered by a single quantity.
Nevertheless, Amazon EBS is community hooked up storage. All information a dealer is writing to an EBS quantity must traverse the community to the Amazon EBS backend. Newer technology occasion households, just like the M5 household, are Amazon EBS-optimized situations with devoted capability for Amazon EBS I/O. However there are limits on the throughput and the IOPS that depend upon the dimensions of the occasion and never solely on the amount dimension. The devoted capability for Amazon EBS gives the next baseline throughput and IOPS for bigger situations. The capability ranges between 81 MB/sec and 2375 MB/sec. For extra info, consult with Supported occasion sorts.
When utilizing Amazon EBS for storage, we will adapt the system for the cluster sustained throughput restrict to acquire a tighter higher sure:
Amazon EC2 community throughput
To this point, we have now solely thought-about community site visitors to the EBS quantity. However replication and the buyer teams additionally trigger Amazon EC2 community site visitors out of the dealer. The site visitors that producers are sending right into a dealer is replicated to r-1 brokers. Furthermore, each shopper group reads the site visitors {that a} dealer ingests. Due to this fact, the general outgoing community site visitors is as follows:
Taking this site visitors under consideration lastly provides us an inexpensive higher sure for the sustained throughput restrict of the cluster, which we have now already seen in Equation 1:
For manufacturing workloads, we suggest holding the precise throughput of your workload beneath 80% of the theoretical sustained throughput restrict because it’s decided by this system. Moreover, we assume that each one information producers despatched into the cluster are ultimately learn by a minimum of one shopper group. When the variety of customers is bigger or equal than 1, the Amazon EC2 community site visitors out of a dealer is at all times larger than the site visitors into the dealer. We are able to due to this fact ignore information site visitors into brokers as a possible bottleneck.
With Equation 1, we will confirm if a cluster with a given infrastructure can take in the throughput required for our workload below splendid circumstances. For extra details about the Amazon EC2 community bandwidth of m5.8xlarge and bigger situations, consult with Amazon EC2 Occasion Varieties. You too can discover the Amazon EBS bandwidth of m5.4xlarge situations on the identical web page. Smaller situations use credit-based methods for Amazon EC2 community bandwidth and the Amazon EBS bandwidth. For the Amazon EC2 community baseline bandwidth, consult with Community efficiency. For the Amazon EBS baseline bandwidth, consult with Supported occasion sorts.
Proper-size your cluster to optimize for efficiency and price
So, what can we take from this? Most significantly, take into account that that these outcomes solely point out the sustained throughput restrict of a cluster below splendid circumstances. These outcomes can provide you a common quantity for the anticipated sustained throughput restrict of your clusters. However it’s essential to run your personal experiments to confirm these outcomes in your particular workload and configuration.
Nevertheless, we will draw a couple of conclusions from this throughput estimation: including brokers will increase the sustained cluster throughput. Equally, reducing the replication issue will increase the sustained cluster throughput. Including a couple of shopper group might scale back the sustained cluster throughput if the Amazon EC2 community turns into the bottleneck.
Let’s run a few experiments to get empirical information on sensible sustained cluster throughput that additionally accounts for producer put latencies. For these assessments, we maintain the throughput inside the advisable 80% of the sustained throughput restrict of clusters. When working your personal assessments, you could discover that clusters may even ship larger throughput than what we present.
Measure Amazon MSK cluster throughput and put latencies
To create the infrastructure for the experiments, we use Amazon Managed Streaming for Apache Kafka (Amazon MSK). Amazon MSK provisions and manages extremely out there Apache Kafka clusters which might be backed by Amazon EBS storage. The next dialogue due to this fact additionally applies to clusters that haven’t been provisioned by Amazon MSK, if backed by EBS volumes.
The experiments are based mostly on the kafka-producer-perf-test.sh and kafka-consumer-perf-test.sh instruments which might be included within the Apache Kafka distribution. The assessments use six producers and two shopper teams with six customers every which might be concurrently studying and writing from the cluster. As talked about earlier than, we ensure that shoppers and brokers are behaving properly and in keeping with greatest practices: producers are evenly balancing the load between brokers, brokers host the identical variety of partitions, customers eat straight from the tip of the stream, producers and customers are over-provisioned in order that they don’t develop into a bottleneck within the measurements, and so forth.
We use clusters which have their brokers deployed to a few Availability Zones. Furthermore, replication is about to 3 and acks is about to all to attain a excessive sturdiness of the information that’s continued within the cluster. We additionally configured a batch.dimension of 256 kB or 512 kB and set linger.ms to five milliseconds, which reduces the overhead of ingesting small batches of information and due to this fact optimizes throughput. The variety of partitions is adjusted to the dealer dimension and cluster throughput.
The configuration for brokers bigger than m5.2xlarge has been tailored in keeping with the steerage of the Amazon MSK Developer Information. Specifically when utilizing provisioned throughput, it’s important to optimize the cluster configuration accordingly.
The next determine compares put latencies for 3 clusters with completely different dealer sizes. For every cluster, the producers are working roughly a dozen particular person efficiency assessments with completely different throughput configurations. Initially, the producers produce a mixed throughput of 16 MB/sec into the cluster and regularly improve the throughput with each particular person check. Every particular person check runs for 1 hour. For situations with burstable efficiency traits, credit are depleted earlier than beginning the precise efficiency measurement.
For brokers with greater than 334 GB of storage, we will assume the EBS quantity has a baseline throughput of 250 MB/sec. The Amazon EBS community baseline throughput is 81.25, 143.75, 287.5, and 593.75 MB/sec for the completely different dealer sizes (for extra info, see Supported occasion sorts). The Amazon EC2 community baseline throughput is 96, 160, 320, and 640 MB/sec (for extra info, see Community efficiency). Observe that this solely considers the sustained throughput; we talk about burst efficiency in a later part.
For a three-node cluster with replication 3 and two shopper teams, the advisable ingress throughput limits as per Equation 1 is as follows.
| Dealer dimension | Really useful sustained throughput restrict |
| m5.massive | 58 MB/sec |
| m5.xlarge | 96 MB/sec |
| m5.2xlarge | 192 MB/sec |
| m5.4xlarge | 200 MB/sec |
Although the m5.4xlarge brokers have twice the variety of vCPUs and reminiscence in comparison with m5.2xlarge brokers, the cluster sustained throughput restrict barely will increase when scaling the brokers from m5.2xlarge to m5.4xlarge. That’s as a result of with this configuration, the EBS quantity utilized by brokers turns into a bottleneck. Do not forget that we’ve assumed a baseline throughput of 250 MB/sec for these volumes. For a three-node cluster and replication issue of three, every dealer wants to write down the identical site visitors to the EBS quantity as is shipped to the cluster itself. And since the 80% of the baseline throughput of the EBS quantity is 200 MB/sec, the advisable sustained throughput restrict of the cluster with m5.4xlarge brokers is 200 MB/sec.
The subsequent part describes how you should use provisioned throughput to extend the baseline throughput of EBS volumes and due to this fact improve the sustained throughput restrict of the whole cluster.
Enhance dealer throughput with provisioned throughput
From the earlier outcomes, you possibly can see that from a pure throughput perspective there’s little profit to rising the dealer dimension from m5.2xlarge to m5.4xlarge with the default cluster configuration. The baseline throughput of the EBS quantity utilized by brokers limits their throughput. Nevertheless, Amazon MSK just lately launched the power to provision storage throughput as much as 1000 MB/sec. For self-managed clusters you should use gp3, io2, or st1 quantity sorts to attain an analogous impact. Relying on the dealer dimension, this could considerably improve the general cluster throughput.
The next determine compares the cluster throughput and put latencies of various dealer sizes and completely different provisioned throughput configurations.
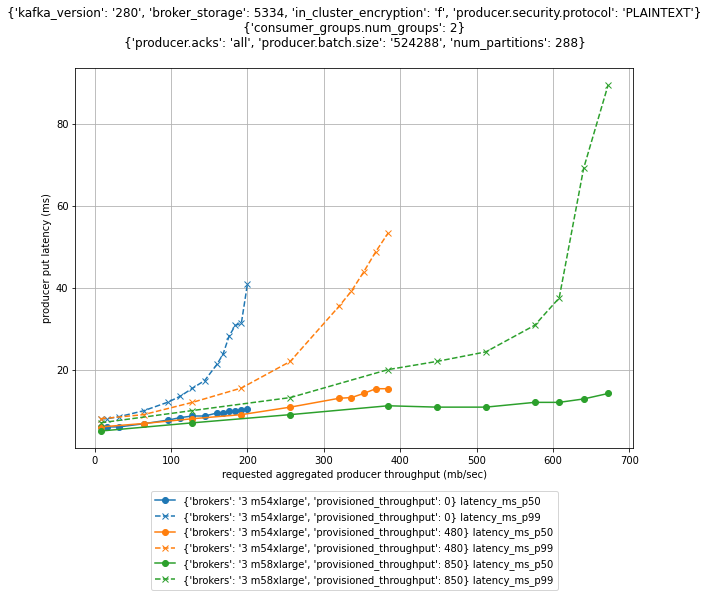
For a three-node cluster with replication 3 and two shopper teams, the advisable ingress throughput limits as per Equation 1 are as follows.
| Dealer dimension | Provisioned throughput configuration | Really useful sustained throughput restrict |
| m5.4xlarge | – | 200 MB/sec |
| m5.4xlarge | 480 MB/sec | 384 MB/sec |
| m5.8xlarge | 850 MB/sec | 680 MB/sec |
| m5.12xlarge | 1000 MB/sec | 800 MB/sec |
| m5.16xlarge | 1000 MB/sec | 800 MB/sec |
The provisioned throughput configuration was rigorously chosen for the given workload. With two shopper teams consuming from the cluster, it doesn’t make sense to extend the provisioned throughput of m4.4xlarge brokers past the 480 MB/sec. The Amazon EC2 community, not the EBS quantity throughput, restricts the advisable sustained throughput restrict of the cluster to 384 MB/sec. However for workloads with a unique variety of customers, it may possibly make sense to additional improve or lower the provisioned throughput configuration to match the baseline throughput of the Amazon EC2 community.
Scale out to extend cluster write throughput
Scaling out the cluster naturally will increase the cluster throughput. However how does this have an effect on efficiency and price? Let’s examine the throughput of two completely different clusters: a three-node m5.4xlarge and a six-node m5.2xlarge cluster, as proven within the following determine. The storage dimension for the m5.4xlarge cluster has been tailored in order that each clusters have the identical complete storage capability and due to this fact the fee for these clusters is equivalent.

The six-node cluster has virtually double the throughput of the three-node cluster and considerably decrease p99 put latencies. Simply ingress throughput of the cluster, it may possibly make sense to scale out fairly than to scale up, in the event you want extra that 200 MB/sec of throughput. The next desk summarizes these suggestions.
| Variety of brokers | Really useful sustained throughput restrict | ||
| m5.massive | m5.2xlarge | m5.4xlarge | |
| 3 | 58 MB/sec | 192 MB/sec | 200 MB/sec |
| 6 | 115 MB/sec | 384 MB/sec | 400 MB/sec |
| 9 | 173 MB/sec | 576 MB/sec | 600 MB/sec |
On this case, we may have additionally used provisioned throughput to extend the throughput of the cluster. Evaluate, as an illustration, the sustained throughput restrict of the six-node m5.2xlarge cluster within the previous determine with that of the three-node m5.4xlarge cluster with provisioned throughput from the sooner instance. The sustained throughput restrict of each clusters is equivalent, which is attributable to the identical Amazon EC2 community bandwidth restrict that often grows proportional with the dealer dimension.
Scale as much as improve cluster learn throughput
The extra shopper teams are studying from the cluster, the extra information egresses over the Amazon EC2 community of the brokers. Bigger brokers have the next community baseline throughput (as much as 25 Gb/sec) and might due to this fact help extra shopper teams studying from the cluster.
The next determine compares how latency and throughput adjustments for the completely different variety of shopper teams for a three-node m5.2xlarge cluster.

As demonstrated on this determine, rising the variety of shopper teams studying from a cluster decreases its sustained throughput restrict. The extra customers that shopper teams are studying from the cluster, the extra information that should egress from the brokers over the Amazon EC2 community. The next desk summarizes these suggestions.
| Shopper teams | Really useful sustained throughput restrict | ||
| m5.massive | m5.2xlarge | m5.4xlarge | |
| 0 | 65 MB/sec | 200 MB/sec | 200 MB/sec |
| 2 | 58 MB/sec | 192 MB/sec | 200 MB/sec |
| 4 | 38 MB/sec | 128 MB/sec | 200 MB/sec |
| 6 | 29 MB/sec | 96 MB/sec | 192 MB/sec |
The dealer dimension determines the Amazon EC2 community throughput, and there’s no option to improve it apart from scaling up. Accordingly, to scale the learn throughput of the cluster, you both must scale up brokers or improve the variety of brokers.
Steadiness dealer dimension and variety of brokers
When sizing a cluster, you usually have the selection to both scale out or scale as much as improve the throughput and efficiency of a cluster. Assuming storage dimension is adjusted accordingly, the price of these two choices is commonly equivalent. So when do you have to scale out or scale up?
Utilizing smaller brokers lets you scale the capability in smaller increments. Amazon MSK enforces that brokers are evenly balanced throughout all configured Availability Zones. You’ll be able to due to this fact solely add quite a few brokers which might be a a number of of the variety of Availability Zones. For example, in the event you add three brokers to a three-node m5.4xlarge cluster with provisioned throughput, you improve the advisable sustained cluster throughput restrict by 100%, from 384 MB/sec to 768 MB/sec. Nevertheless, in the event you add three brokers to a six-node m5.2xlarge cluster, you improve the advisable cluster throughput restrict by 50%, from 384 MB/sec to 576 MB/sec.
Having too few very massive brokers additionally will increase the blast radius in case a single dealer is down for upkeep or due to failure of the underlying infrastructure. For example, for a three-node cluster, a single dealer corresponds to 33% of the cluster capability, whereas it’s solely 17% for a six-node cluster. When provisioning clusters to greatest practices, you may have added sufficient spare capability to not affect your workload throughout these operations. However for bigger brokers, you could want so as to add extra spare capability than required due to the bigger capability increments.
Nevertheless, the extra brokers are a part of the cluster, the longer it takes for upkeep and replace operations to finish. The service applies these adjustments sequentially to 1 dealer at a time to reduce affect to the provision of the cluster. When provisioning clusters to greatest practices, you may have added sufficient spare capability to not affect your workload throughout these operations. However the time it takes to finish the operation continues to be one thing to think about as a result of it’s good to look ahead to one operation to finish earlier than you possibly can run one other one.
That you must discover a stability that works in your workload. Small brokers are extra versatile as a result of they provide you smaller capability increments. However having too many small brokers will increase the time it takes for upkeep operations to finish and improve the probability for failure. Clusters with fewer bigger brokers full replace operations sooner. However they arrive with bigger capability increments and the next blast radius in case of dealer failure.
Scale up for CPU intensive workloads
To this point, we have now we have now targeted on the community throughput of brokers. However there are different elements that decide the throughput and latency of the cluster. One in every of them is encryption. Apache Kafka has a number of layers the place encryption can defend information in transit and at relaxation: encryption of the information saved on the storage volumes, encryption of site visitors between brokers, and encryption of site visitors between shoppers and brokers.
Amazon MSK at all times encrypts your information at relaxation. You’ll be able to specify the AWS Key Administration Service (AWS KMS) buyer grasp key (CMK) that you really want Amazon MSK to make use of to encrypt your information at relaxation. In the event you don’t specify a CMK, Amazon MSK creates an AWS managed CMK for you and makes use of it in your behalf. For information that’s in-flight, you possibly can select to allow encryption of knowledge between producers and brokers (in-transit encryption), between brokers (in-cluster encryption), or each.
Turning on in-cluster encryption forces the brokers to encrypt and decrypt particular person messages. Due to this fact, sending messages over the community can now not benefit from the environment friendly zero copy operation. This ends in further CPU and reminiscence bandwidth overhead.
The next determine reveals the efficiency affect for these choices for three-node clusters with m5.massive and m5.2xlarge brokers.
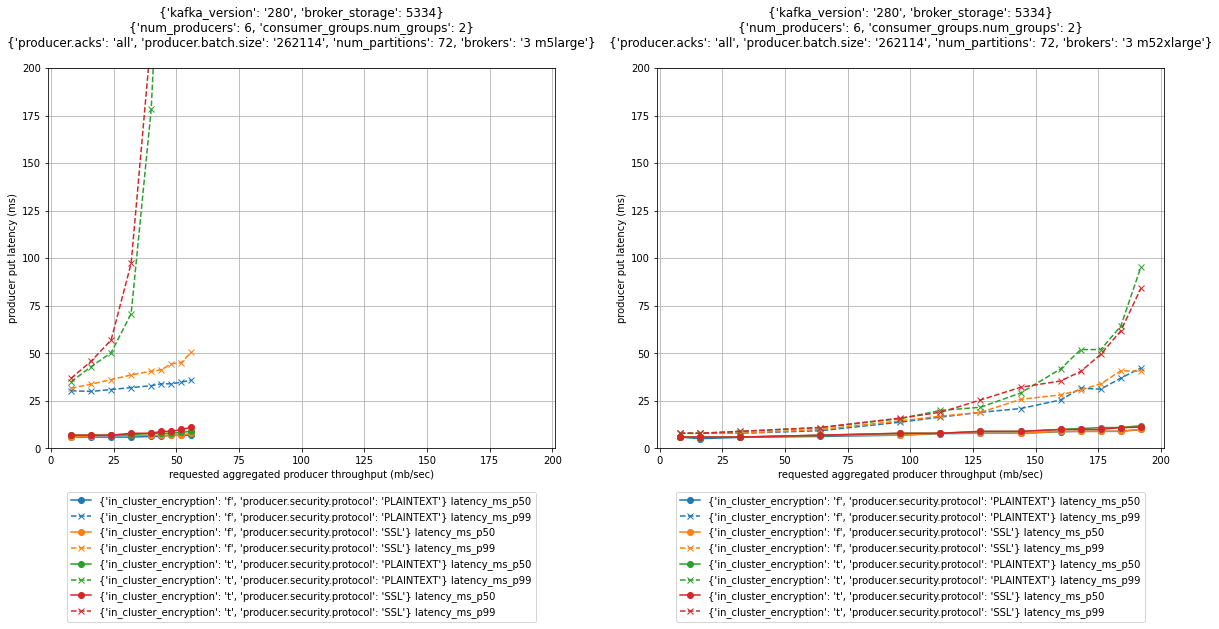
For p99 put latencies, there’s a substantial efficiency affect of enabling in-cluster encryption. As proven within the previous graphs, scaling up brokers can mitigate the impact. The p99 put latency at 52 MB/sec throughput of an m5.massive cluster with in-transit and in-cluster encryption is above 200 milliseconds (purple and inexperienced dashed line within the left graph). Scaling the cluster to m5.2xlarge brokers brings down the p99 put latency on the similar throughput to beneath 15 milliseconds (purple and inexperienced dashed line in the fitting graph).
There are different elements that may improve CPU necessities. Compression in addition to log compaction may affect the load on clusters.
Scale up for a shopper not studying from the tip of the stream
We now have designed the efficiency assessments such that buyers are at all times studying from the tip of the subject. This successfully signifies that brokers can serve the reads from customers straight from reminiscence, not inflicting any learn I/O to Amazon EBS. In distinction to all different sections of the publish, we drop this assumption to know how customers which have fallen behind can affect cluster efficiency. The next diagram illustrates this design.

When a shopper falls behind or must get well from failure it reprocesses older messages. In that case, the pages holding the information might now not reside within the web page cache, and brokers must fetch the information from the EBS quantity. That causes further community site visitors to the amount and non-sequential I/O reads. This could considerably affect the throughput of the EBS quantity.
In an excessive case, a backfill operation can reprocess the entire historical past of occasions. In that case, the operation not solely causes further I/O to the EBS quantity, it additionally masses numerous pages holding historic information into the web page cache, successfully evicting pages which might be holding more moderen information. Consequently, customers which might be barely behind the tip of the subject and would often learn straight from the web page cache might now trigger further I/O to the EBS quantity as a result of the backfill operation has evicted the web page they should learn from reminiscence.
One choice to mitigate these situations is to allow compression. By compressing the uncooked information, brokers can maintain extra information within the web page cache earlier than it’s evicted from reminiscence. Nevertheless, take into account that compression requires extra CPU assets. In the event you can’t allow compression or if enabling compression can’t mitigate this situation, you may as well improve the dimensions of the web page cache by rising the reminiscence out there to brokers by scaling up.
Use burst efficiency to accommodate site visitors spikes
To this point, we’ve been trying on the sustained throughput restrict of clusters. That’s the throughput the cluster can maintain indefinitely. For streaming workloads, it’s vital to know baseline the throughput necessities and dimension accordingly. Nevertheless, the Amazon EC2 community, Amazon EBS community, and Amazon EBS storage system are based mostly on a credit score system; they supply a sure baseline throughput and might burst to the next throughput for a sure interval based mostly on the occasion dimension. This straight interprets to the throughput of MSK clusters. MSK clusters have a sustained throughput restrict and might burst to the next throughput for brief intervals.
The blue line within the following graph reveals the combination throughput of a three-node m5.massive cluster with two shopper teams. Throughout the whole experiment, producers are attempting to ship information as shortly as potential into the cluster. So, though 80% of the sustained throughput restrict of the cluster is round 58 MB/sec, the cluster can burst to a throughput properly above 200 MB/sec for nearly half an hour.

Consider it this manner: When configuring the underlying infrastructure of a cluster, you’re mainly provisioning a cluster with a sure sustained throughput restrict. Given the burst capabilities, the cluster can then instantaneously take in a lot larger throughput for a while. For example, if the common throughput of your workload is often round 50 MB/sec, the three-node m5.massive cluster within the previous graph can ingress greater than 4 instances its typical throughput for roughly half an hour. And that’s with none adjustments required. This burst to the next throughput is totally clear and doesn’t require any scaling operation.
It is a very highly effective option to take in sudden throughput spikes with out scaling your cluster, which takes time to finish. Furthermore, the extra capability additionally helps in response to operational occasions. For example, when brokers are present process upkeep or partitions have to be rebalanced inside the cluster, they’ll use burst efficiency to get brokers on-line and again in sync extra shortly. The burst capability can also be very worthwhile to shortly get well from operational occasions that have an effect on a complete Availability Zone and trigger numerous replication site visitors in response to the occasion.
Monitoring and steady optimization
To this point, we have now targeted on the preliminary sizing of your cluster. However after you identify the proper preliminary cluster dimension, the sizing efforts shouldn’t cease. It’s vital to maintain reviewing your workload after it’s working in manufacturing to know if the dealer dimension continues to be acceptable. Your preliminary assumptions might now not maintain in follow, or your design targets might need modified. In spite of everything, one of many nice advantages of cloud computing is that you would be able to adapt the underlying infrastructure by an API name.
As we have now talked about earlier than, the throughput of your manufacturing clusters ought to goal 80% of their sustained throughput restrict. When the underlying infrastructure is beginning to expertise throttling as a result of it has exceeded the throughput restrict for too lengthy, it’s good to scale up the cluster. Ideally, you’d even scale the cluster earlier than it reaches this level. By default, Amazon MSK exposes three metrics that point out when this throttling is utilized to the underlying infrastructure:
- BurstBalance – Signifies the remaining stability of I/O burst credit for EBS volumes. If this metric begins to drop, take into account rising the dimensions of the EBS quantity to extend the amount baseline efficiency. If Amazon CloudWatch isn’t reporting this metric in your cluster, your volumes are bigger than 5.3 TB and now not topic to burst credit.
- CPUCreditBalance – Solely related for brokers of the T3 household and signifies the quantity of obtainable CPU credit. When this metric begins to drop, brokers are consuming CPU credit to burst past their CPU baseline efficiency. Contemplate altering the dealer kind to the M5 household.
- TrafficShaping – A high-level metric indicating the variety of packets dropped resulting from exceeding community allocations. Finer element is accessible when the
PER_BROKERmonitoring stage is configured for the cluster. Scale up brokers if this metric is elevated throughout your typical workloads.
Within the earlier instance, we noticed the cluster throughput drop considerably after community credit have been depleted and site visitors shaping was utilized. Even when we didn’t know the utmost sustained throughput restrict of the cluster, the TrafficShaping metric within the following graph clearly signifies that we have to scale up the brokers to keep away from additional throttling on the Amazon EC2 community layer.

Amazon MSK exposes further metrics that provide help to perceive whether or not your cluster is over- or under-provisioned. As a part of the sizing train, you may have decided the sustained throughput restrict of your cluster. You’ll be able to monitor and even create alarms on the BytesInPerSec, ReplicationBytesInPerSec, BytesOutPerSec, and ReplicationBytesInPerSec metrics of the cluster to obtain notification when the present cluster dimension is now not optimum for the present workload traits. Likewise, you possibly can monitor the CPUIdle metric and alarm when your cluster is under- or over-provisioned by way of CPU utilization.
These are solely probably the most related metrics to observe the dimensions of your cluster from an infrastructure perspective. You must also monitor the well being of the cluster and the whole workload. For additional steerage on monitoring clusters, consult with Finest Practices.
A framework for testing Apache Kafka efficiency
As talked about earlier than, it’s essential to run your personal assessments to confirm if the efficiency of a cluster matches your particular workload traits. We now have revealed a efficiency testing framework on GitHub that helps automate the scheduling and visualization of many assessments. We now have been utilizing the identical framework to generate the graphs that we have now been discussing on this publish.
The framework relies on the kafka-producer-perf-test.sh and kafka-consumer-perf-test.sh instruments which might be a part of the Apache Kafka distribution. It builds automation and visualization round these instruments.
For smaller brokers which might be topic to bust capabilities, you may as well configure the framework to first generate extra load over an prolonged interval to deplete networking, storage, or storage community credit. After the credit score depletion completes, the framework runs the precise efficiency check. That is vital to measure the efficiency of clusters that may be sustained indefinitely fairly than measuring peak efficiency, which may solely be sustained for a while.
To run your personal check, consult with the GitHub repository, the place you’ll find the AWS Cloud Improvement Equipment (AWS CDK) template and extra documentation on how you can configure, run, and visualize the outcomes of efficiency check.
Conclusion
We’ve mentioned varied elements that contribute to the efficiency of Apache Kafka from an infrastructure perspective. Though we’ve targeted on Apache Kafka, we additionally realized about Amazon EC2 networking and Amazon EBS efficiency traits.
To seek out the fitting dimension in your clusters, work backward out of your use case to find out the throughput, availability, sturdiness, and latency necessities.
Begin with an preliminary sizing of your cluster based mostly in your throughput, storage, and sturdiness necessities. Scale out or use provisioned throughput to extend the write throughput of the cluster. Scale as much as improve the variety of customers that may eat from the cluster. Scale as much as facilitate in-transit or in-cluster encryption and customers that aren’t studying type the tip of the stream.
Confirm this preliminary cluster sizing by working efficiency assessments after which fine-tune the cluster dimension and configuration to match different necessities, corresponding to latency. Add further capability for manufacturing clusters in order that they’ll stand up to the upkeep or lack of a dealer. Relying in your workload, you could even take into account withstanding an occasion affecting a complete Availability Zone. Lastly, maintain monitoring your cluster metrics and resize the cluster in case your preliminary assumptions now not maintain.
In regards to the Writer
 Steffen Hausmann is a Principal Streaming Architect at AWS. He works with clients across the globe to design and construct streaming architectures in order that they’ll get worth from analyzing their streaming information. He holds a doctorate diploma in pc science from the College of Munich and in his free time, he tries to lure his daughters into tech with cute stickers he collects at conferences.
Steffen Hausmann is a Principal Streaming Architect at AWS. He works with clients across the globe to design and construct streaming architectures in order that they’ll get worth from analyzing their streaming information. He holds a doctorate diploma in pc science from the College of Munich and in his free time, he tries to lure his daughters into tech with cute stickers he collects at conferences.


{kind=link}