
[ad_1]
Organizations sometimes accumulate large volumes of information and proceed to generate ever-exceeding information volumes, starting from terabytes to petabytes and at occasions to exabytes of information. Such information is often generated in disparate techniques and requires an aggregation right into a single location for evaluation and perception technology. An information lake structure means that you can combination information current in varied silos, retailer it in a centralized repository, implement information governance, and help analytics and machine studying (ML) on high of this saved information.
Typical constructing blocks to implement such an structure embody a centralized repository constructed on Amazon Easy Storage Service (Amazon S3) offering the least potential unit price of storage per GB, large information ETL (extract, remodel, and cargo) frameworks akin to AWS Glue, and analytics utilizing Amazon Athena, Amazon Redshift, and Amazon EMR notebooks.
Constructing such techniques entails technical challenges. For instance, information residing in S3 buckets can’t be up to date in-place utilizing commonplace information ingestion approaches. Subsequently, you will need to carry out fixed ad-hoc ETL jobs to consolidate information into new S3 recordsdata and buckets.
That is particularly the case with streaming sources, which require fixed help for growing information velocity to supply quicker insights technology. An instance use case could be an ecommerce firm seeking to construct a real-time date lake. They want their answer to do the next:
- Ingest steady modifications (like buyer orders) from upstream techniques
- Seize tables into the information lake
- Present ACID properties on the information lake to help interactive analytics by enabling constant views on information whereas new information is being ingested
- Present schema flexibility on account of upstream information structure modifications and provisions for late arrival of information
To ship on these necessities, organizations should construct customized frameworks to deal with in-place updates (additionally referred as upserts), deal with small recordsdata created because of the steady ingestion of modifications from upstream techniques (akin to databases), deal with schema evolution, and compromise on offering ACID ensures on its information lake.
A processing framework like Apache Hudi could be a great way remedy such challenges. Hudi means that you can construct streaming information lakes with incremental information pipelines, with help for transactions, record-level updates, and deletes on information saved in information lakes. Hudi is built-in with varied AWS analytics providers, like AWS Glue, Amazon EMR, Athena, and Amazon Redshift. This helps you ingest information from a wide range of sources through batch streaming whereas enabling in-place updates to an append-oriented storage system akin to Amazon S3 (or HDFS). On this publish, we talk about a serverless method to combine Hudi with a streaming use case and create an in-place updatable information lake on Amazon S3.
Resolution overview
We use Amazon Kinesis Information Generator to ship pattern streaming information to Amazon Kinesis Information Streams. To eat this streaming information, we arrange an AWS Glue streaming ETL job that makes use of the Apache Hudi Connector for AWS Glue to write down ingested and reworked information to Amazon S3, and in addition creates a desk within the AWS Glue Information Catalog.
After the information is ingested, Hudi organizes a dataset right into a partitioned listing construction underneath a base path pointing to a location in Amazon S3. Information structure in these partitioned directories is determined by the Hudi dataset kind used throughout ingestion, akin to Copy on Write (CoW) and Merge on Learn (MoR). For extra details about Hudi storage varieties, see Utilizing Athena to Question Apache Hudi Datasets and Storage Sorts & Views.
CoW is the default storage kind of Hudi. On this storage kind, information is saved in columnar format (Parquet). Every ingestion creates a brand new model of recordsdata throughout a write. With CoW, every time there may be an replace to a report, Hudi rewrites the unique columnar file containing the report with the up to date values. Subsequently, that is higher suited to read-heavy workloads on information that modifications much less often.
The MoR storage kind is saved utilizing a mix of columnar (Parquet) and row-based (Avro) codecs. Updates are logged to row-based delta recordsdata and are compacted to create new variations of columnar recordsdata. With MoR, every time there may be an replace to a report, Hudi writes solely the row for the modified report into the row-based (Avro) format, which is compacted (synchronously or asynchronously) to create columnar recordsdata. Subsequently, MoR is best suited to write or change-heavy workloads with a lesser quantity of learn.
For this publish, we use the CoW storage kind as an example our use case of making a Hudi dataset and serving the identical through a wide range of readers. You possibly can lengthen this answer to help MoR storage through choosing the precise storage kind throughout ingestion. We use Athena to learn the dataset. We additionally illustrate the capabilities of this answer by way of in-place updates, nested partitioning, and schema flexibility.
The next diagram illustrates our answer structure.
Create the Apache Hudi connection utilizing the Apache Hudi Connector for AWS Glue
To create your AWS Glue job with an AWS Glue customized connector, full the next steps:
- On the AWS Glue Studio console, select Market within the navigation pane.
- Seek for and select Apache Hudi Connector for AWS Glue.

- Select Proceed to Subscribe.

- Evaluate the phrases and situations and select Settle for Phrases.

- Guarantee that the subscription is full and also you see the Efficient date populated subsequent to the product, then select Proceed to Configuration.

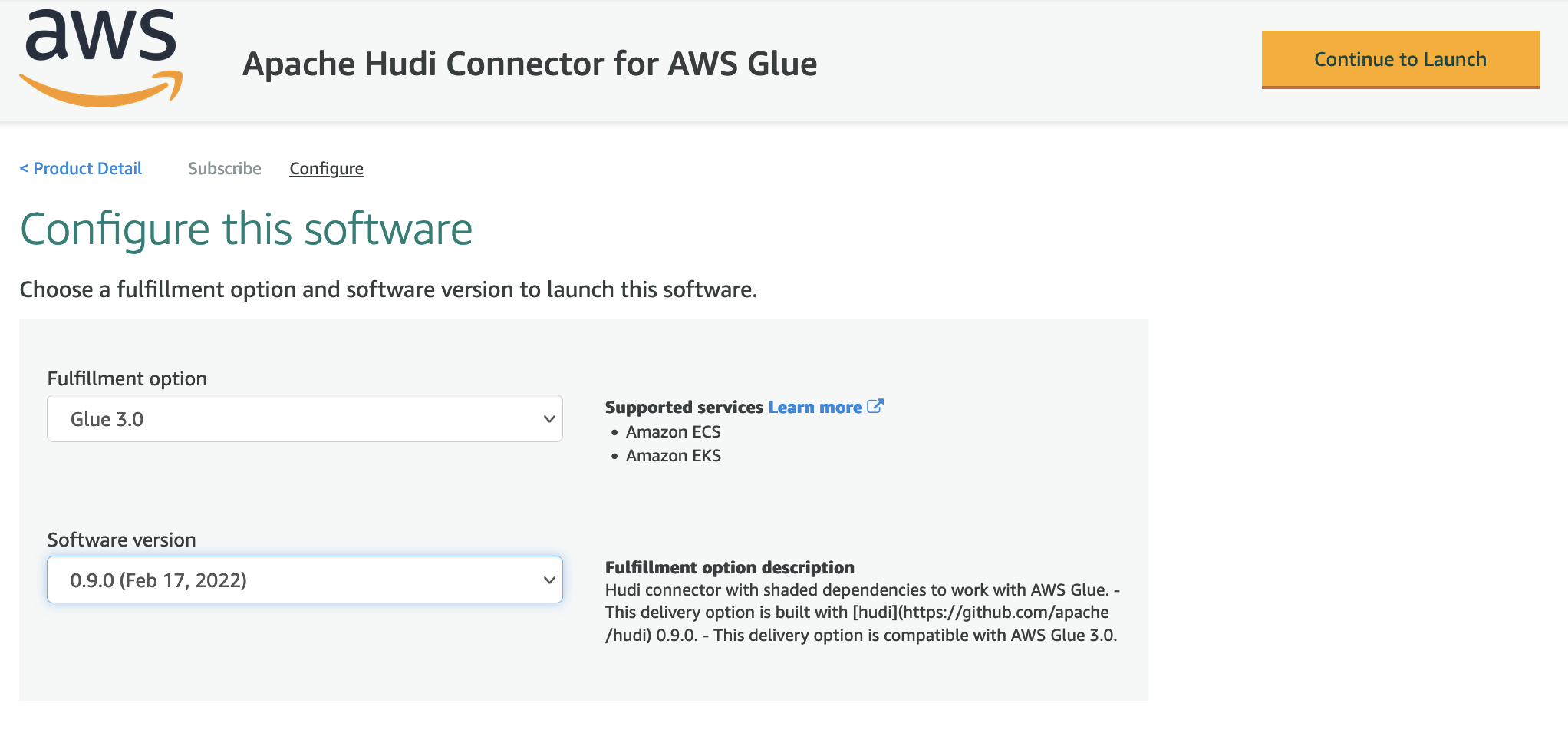
- For Supply Methodology, select Glue 3.0.
- For Software program Model, select the most recent model (as of this writing, 0.9.0 is the most recent model of the Apache Hudi Connector for AWS Glue).
- Select Proceed to Launch.

- Below Launch this software program, select Utilization Directions after which select Activate the Glue connector for Apache Hudi in AWS Glue Studio.



You’re redirected to AWS Glue Studio.
- For Title, enter a reputation in your connection (for instance, hudi-connection).
- For Description, enter an outline.
- Select Create connection and activate connector.


A message seems that the connection was efficiently created, and the connection is now seen on the AWS Glue Studio console.
Configure assets and permissions
For this publish, we offer an AWS CloudFormation template to create the next assets:
- An S3 bucket named
hudi-demo-bucket-<your-stack-id>that incorporates a JAR artifact copied from one other public S3 bucket outdoors of your account. This JAR artifact is then used to outline the AWS Glue streaming job. - A Kinesis information stream named
hudi-demo-stream-<your-stack-id>. - An AWS Glue streaming job named
Hudi_Streaming_Job-<your-stack-id>with a devoted AWS Glue Information Catalog namedhudi-demo-db-<your-stack-id>. Confer with the aws-samples github repository for the entire code of the job. - AWS Id and Entry Administration (IAM) roles and insurance policies with applicable permissions.
- AWS Lambda features to repeat artifacts to the S3 bucket and empty buckets first upon stack deletion.
To create your assets, full the next steps:
- Select Launch Stack:

- For Stack identify, enter
hudi-connector-blog-for-streaming-data. - For HudiConnectionName, use the identify you specified within the earlier part.
- Depart the opposite parameters as default.
- Select Subsequent.

- Choose I acknowledge that AWS CloudFormation would possibly create IAM assets with customized names.
- Select Create stack.

Arrange Kinesis Information Generator
On this step, you configure Kinesis Information Generator to ship pattern information to a Kinesis information stream.
- On the Kinesis Information Generator console, select Create a Cognito Consumer with CloudFormation.


You’re redirected to the AWS CloudFormation console.
- On the Evaluate web page, within the Capabilities part, choose I acknowledge that AWS CloudFormation would possibly create IAM assets.
- Select Create stack.
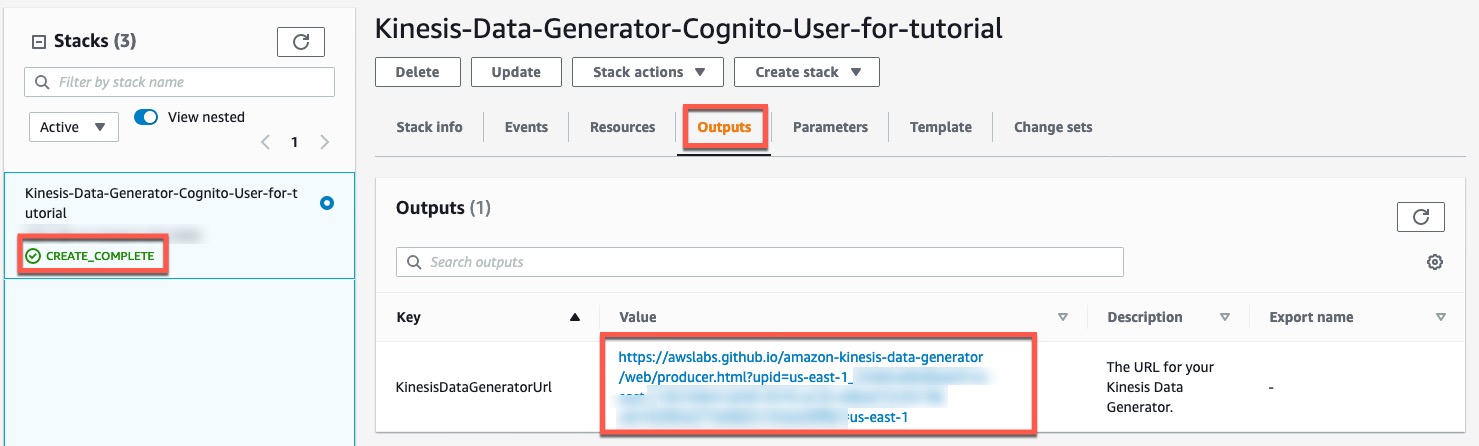
- On the Stack particulars web page, within the Stacks part, confirm that the standing exhibits
CREATE_COMPLETE. - On the Outputs tab, copy the URL worth for
KinesisDataGeneratorUrl.
- Navigate to this URL in your browser.
- Enter the person identify and password offered and select Signal In.
Begin an AWS Glue streaming job
To start out an AWS Glue streaming job, full the next steps:
- On the AWS CloudFormation console, navigate to the Sources tab of the stack you created.
- Copy the bodily ID equivalent to the AWS::Glue::Job useful resource.

- On the AWS Glue Studio console, discover the job identify utilizing the bodily ID.
- Select the job to evaluation the script and job particulars.

- Select Run to begin the job.

- On the Runs tab, validate if the job is efficiently operating.





Ship pattern information to a Kinesis information stream
Kinesis Information Generator generates data utilizing random information based mostly on a template you present. Kinesis Information Generator extends faker.js, an open-source random information generator.
On this step, you utilize Kinesis Information Generator to ship pattern information utilizing a pattern template utilizing the faker.js documentation to the beforehand created information stream created at one report per second charge. You maintain the ingestion till the tip of this tutorial to attain affordable information for evaluation whereas performing the remaining steps.
- On the Kinesis Information Generator console, for Data per second, select the Fixed tab, and alter the worth to
1. - For Report template, select the Template 1 tab, and enter the next code pattern into the textual content field:
- Select Take a look at template.

- Confirm the construction of the pattern JSON data and select Shut.

- Select Ship information.
- Depart the Kinesis Information Generator web page open to make sure sustained streaming of random data into the information stream.


{kind=link}
Proceed by way of the remaining steps when you generate your information.
Confirm dynamically created assets
Whilst you’re producing information for evaluation, you possibly can confirm the assets you created.
Amazon S3 dataset
When the AWS Glue streaming job runs, the data from the Kinesis information stream are consumed and saved in an S3 bucket. Whereas creating Hudi datasets in Amazon S3, the streaming job may create a nested partition construction. That is enabled by way of the utilization of Hudi configuration properties hoodie.datasource.write.partitionpath.area and hoodie.datasource.write.keygenerator.class within the streaming job definition.
On this instance, nested partitions have been created by identify, 12 months, month, and day. The values of those properties are set as follows within the script for the AWS Glue streaming job.
For additional particulars on how CustomKeyGenerator works to generate such partition paths, check with Apache Hudi Key Turbines.
The next screenshot exhibits the nested partitions created in Amazon S3.
AWS Glue Information Catalog desk
A Hudi desk can also be created within the AWS Glue Information Catalog and mapped to the Hudi datasets on Amazon S3. See the next code within the AWS Glue streaming job.
The next desk gives extra particulars on the configuration choices.
The next screenshot exhibits the Hudi desk within the Information Catalog and the related S3 bucket.
Learn outcomes utilizing Athena
Utilizing Hudi with an AWS Glue streaming job permits us to have in-place updates (upserts) on the Amazon S3 information lake. This performance permits for incremental processing, which permits quicker and extra environment friendly downstream pipelines. Apache Hudi permits in-place updates with the next steps:
- Outline an index (utilizing columns of the ingested report).
- Use this index to map each subsequent ingestion to the report storage areas (in our case Amazon S3) ingested beforehand.
- Carry out compaction (synchronously or asynchronously) to permit the retention of the most recent report for a given index.
In reference to our AWS Glue streaming job, the next Hudi configuration choices allow us to attain in-place updates for the generated schema.
The next desk gives extra particulars of the highlighted configuration choices.
To show an in-place replace, contemplate the next enter data despatched to the AWS Glue streaming job through Kinesis Information Generator. The report identifier highlighted signifies the Hudi report key within the AWS Glue configuration. On this instance, Person3 receives two updates. In first replace, column_to_update_string is ready to White; within the second replace, it’s set to Pink.
The streaming job processes these data and creates the Hudi datasets in Amazon S3. You possibly can question the dataset utilizing Athena. Within the following instance, we get the most recent replace.
Schema flexibility
The AWS Glue streaming job permits for computerized dealing with of various report schemas encountered throughout the ingestion. That is particularly helpful in conditions the place report schemas could be topic to frequent modifications. To elaborate on this level, contemplate the next situation:
- Case 1 – At time t1, the ingested report has the structure
<col 1, col 2, col 3, col 4> - Case 2 – At time t2, the ingested report has an additional column, with new structure
<col 1, col 2, col 3, col 4, col 5> - Case 3 – At time t3, the ingested report dropped the additional column and due to this fact has the structure
<col 1, col 2, col 3, col 4>
For Case 1 and a couple of, the AWS Glue streaming job depends on the built-in schema evolution capabilities of Hudi, which permits an replace to the Information Catalog with the additional column (col 5 on this case). Moreover, Hudi additionally provides an additional column within the output recordsdata (Parquet recordsdata written to Amazon S3). This enables for the querying engine (Athena) to question the Hudi dataset with an additional column with none points.
As a result of Case 2 ingestion updates the Information Catalog, the additional column (col 5) is anticipated to be current in each subsequent ingested report. If we don’t resolve this distinction, the job fails.
To beat this and obtain Case 3, the streaming job defines a customized perform named evolveSchema, which handles the report structure mismatches. The strategy queries the AWS Glue Information Catalog for every to-be-ingested report and will get the present Hudi desk schema. It then merges the Hudi desk schema with the schema of the to-be-ingested report and enriches the schema of the report earlier than exposing with the Hudi dataset.
For this instance, the to-be-ingested report’s schema <col 1, col 2, col 3, col 4> is modified to <col 1, col 2, col 3, col 4, col 5>, the place the worth of the additional col 5 is ready to NULL.
For example this, we cease the present ingestion of Kinesis Information Generator and modify the report structure to ship an additional column known as new_column:

The Hudi desk within the Information Catalog updates as follows, with the newly added column (Case 2).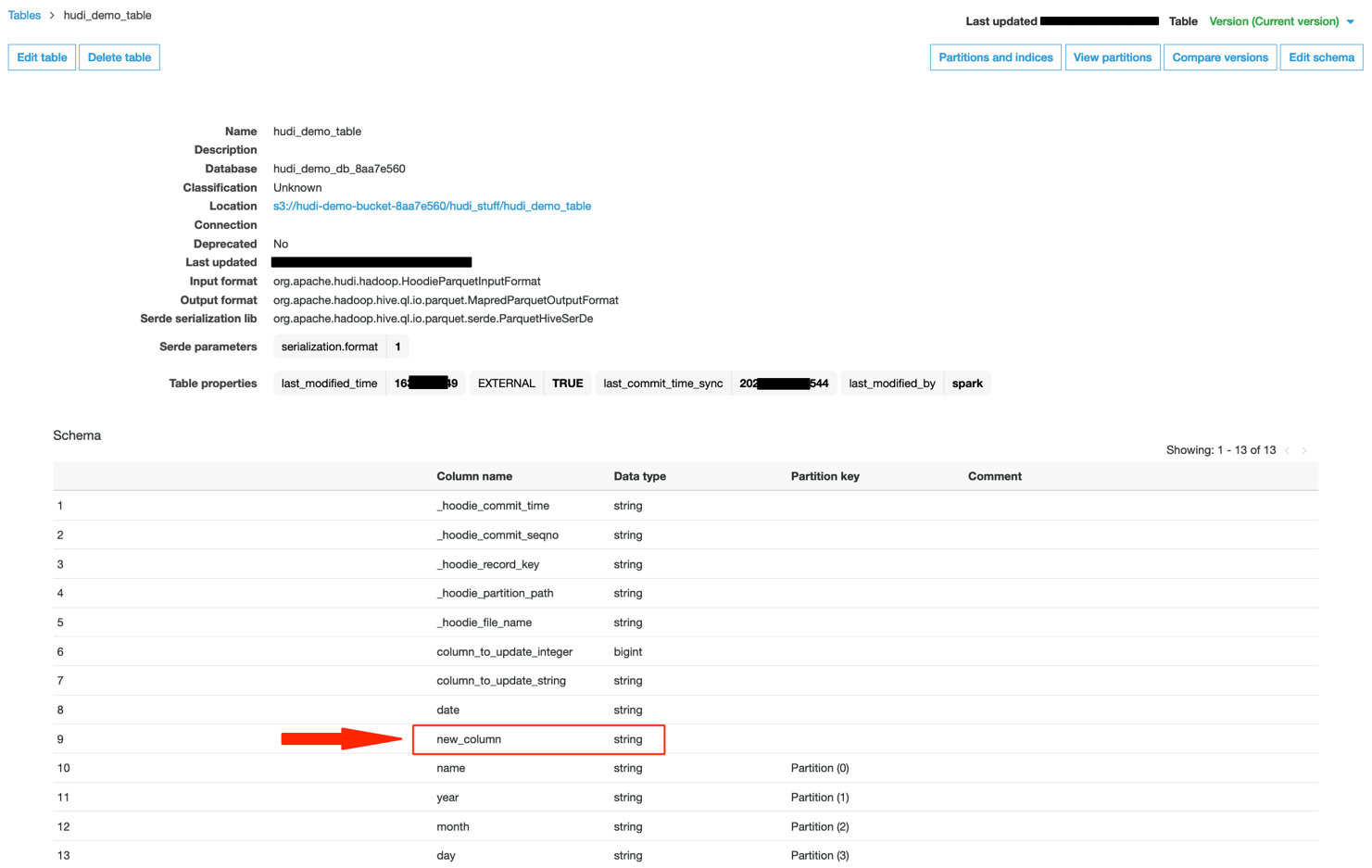
Once we question the Hudi dataset utilizing Athena, we are able to see the presence of a brand new column.
We will now use Kinesis Information Generator to ship data with an previous schema—with out the newly added column (Case 3).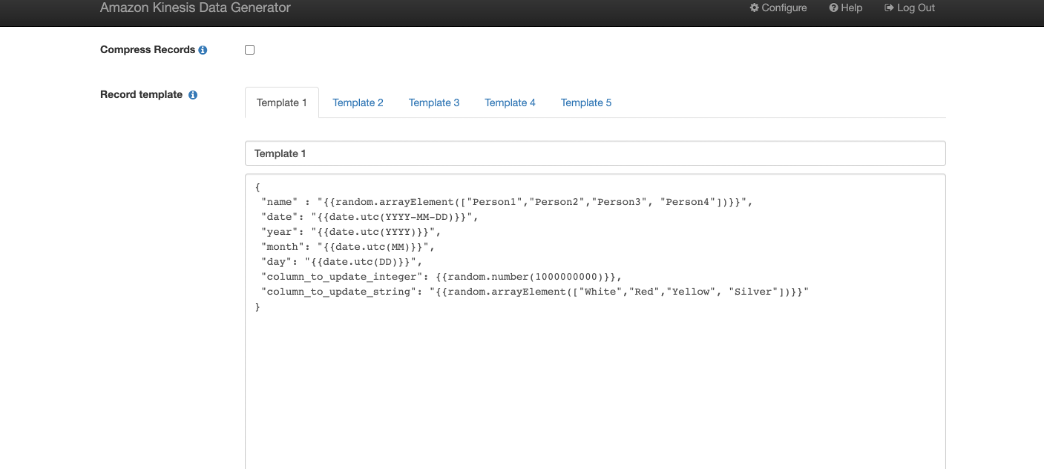
On this situation, our AWS Glue job retains operating. Once we question utilizing Athena, the additional added column will get populated with NULL values.
If we cease Kinesis Information Generator and begin sending data with a schema containing additional columns, the job retains operating and the Athena question continues to return the most recent values.
Clear up
To keep away from incurring future fees, delete the assets you created as a part of the CloudFormation stack.
Abstract
This publish illustrated arrange a serverless pipeline utilizing an AWS Glue streaming job with the Apache Hudi Connector for AWS Glue, which runs constantly and consumes information from Kinesis Information Streams to create a near-real-time information lake that helps in-place updates, nested partitioning, and schema flexibility.
You can even use Apache Kafka and Amazon Managed Streaming for Apache Kafka (Amazon MSK) because the supply of an identical streaming job. We encourage you to make use of this method for establishing a near-real-time information lake. As all the time, AWS welcomes suggestions, so please go away your ideas or questions within the feedback.
Concerning the Authors
 Nikhil Khokhar is a Options Architect at AWS. He joined AWS in 2016 and makes a speciality of constructing and supporting information streaming options that assist clients analyze and get worth out of their information. In his free time, he makes use of his 3D printing expertise to unravel on a regular basis issues.
Nikhil Khokhar is a Options Architect at AWS. He joined AWS in 2016 and makes a speciality of constructing and supporting information streaming options that assist clients analyze and get worth out of their information. In his free time, he makes use of his 3D printing expertise to unravel on a regular basis issues.
 Dipta S Bhattacharya is a Options Architect Supervisor at AWS. Dipta joined AWS in 2018. He works with massive startup clients to design and develop architectures on AWS and help their journey on the cloud.
Dipta S Bhattacharya is a Options Architect Supervisor at AWS. Dipta joined AWS in 2018. He works with massive startup clients to design and develop architectures on AWS and help their journey on the cloud.
[ad_2]