
{kind=link}
When you have written exterior information switch performance for ERP software program on your enterprise, then you have got positively come throughout built-in utilities which allow you to create information information that may be despatched out to profit suppliers, state governments, and anybody else who could must course of information associated to staff in your group. These utilities are a really nifty function that makes such information transfers a comparably clean and easy course of.
However what for those who or a non-technical individual desires to overview the information? Whereas most of this information is normally textual content, it’s usually not written in an easy-to-process format, like a CSV file or a tab-delimited file. And, whereas it’s attainable to look at these information immediately in a textual content editor like BBEdit or Notepad++, having to trace space-delimited fields with totally different varieties of information bunched up subsequent to one another will be complicated. With that in thoughts, in at present’s Python programming tutorial, we’ll have a look at how you can extract textual content from tough file codecs utilizing Python code.
Learn: 6 Greatest Python IDEs and Code Editors
What’s Textual content Scraping?
Textual content scraping is the method of utilizing a program or script to learn information from any information stream, akin to a file, after which representing that information in a structured format that may be extra simply managed or processed. That is usually achieved by means of common expressions (Regex) and filtering instruments akin to grep. Nevertheless, programming languages like C#, Python, and PHP embody sturdy string processing libraries which make this course of a lot simpler for somebody who is probably not fluent in common expressions, or who doesn’t wish to make investments the time wanted to grow to be fluent in them.
This text makes use of Python 3 for the code samples and presumes that you simply, because the reader, have a fundamental working data of Python, however these strategies will be finished in most different programming languages as properly. Earlier than you start, it’s possible you’ll wish to learn our article Overview of Common Expressions and Regex in Python.
Parsing Information in Python
Efficient textual content scraping means understanding the place, inside the information stream, the knowledge that you’re in search of exists. If the information supply is the HTML code of an online web page, you would want to have the ability to readily establish that inside its supply code. If the information supply is a file that makes use of a number of strains for a single information document, then you definitely would want to know the beginning and ending factors of the knowledge you want. There isn’t any one mounted mechanism for figuring this out. You will have to take a look at the file to see what, if any, patterns exist within the information.
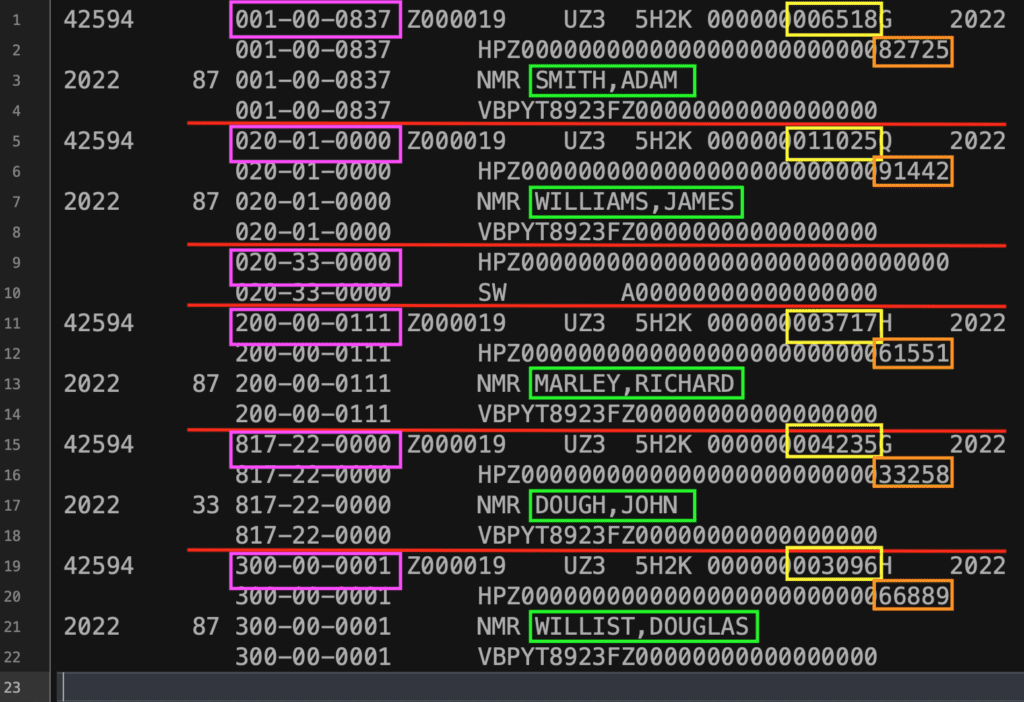
For instance, say your supply information had the pattern contents under, and this info represented medical health insurance cost info for every worker who elected to have medical health insurance:

Observe: It is extremely frequent for textual content editors which are bundled with Home windows or Mac OSX, akin to Notepad or TextEdit, respectively, to make use of proportional fonts by default. This ends in elevated problem in attempting to determine a file format. Both configure these editors to make use of a fixed-width font like Courier New, or use editors like Notepad++ for Home windows or BBEdit for Mac OSX.
It’s fairly straightforward to parse out issues like first names, final names, and Social Safety Numbers from this pattern information. However say that for the sake of this instance, this information may very well be damaged up within the following methods:
Learn: High On-line Programs to Be taught Python
It’s straightforward to conclude {that a} single document of data could be composed of the varied information from the objects scattered between every of the pink strains within the determine above. On this case, a single document could be composed of:
-
- Social Safety Quantity (SSN)
- First Title and Final Title, delimited by a comma
- Two numerical quantities which differ by every worker. In lots of the output information which are created by ERP software program, this could check with quantities of cash that an worker could also be contributing to a retirement plan, or paying for an insurance coverage profit. For this text, these will probably be presumed to be:
- A “nonsense” month-to-month quantity, represented by the yellow spotlight.
- A “nonsense” yearly quantity, represented by the orange spotlight.
These information can differ radically in formatting and the type of info they include, but when you know the way to take a look at the file, you’ll be able to positively pluck out the numerous parts that you’d wish to embody in an easier-to-use format. This may embody demographic objects like:
-
- Cellphone numbers
- Electronic mail addresses
- Dates of Start
- Dwelling mailing addresses
- Dependent info
- Profit Plan Codes
When you have entry to an worker’s info throughout the ERP, or in case your enterprise allows you to have such entry, you’ll be able to look at an worker’s info to find out which numbers or symbols correspond to the objects you may even see in an ERP-generated file.
Discover the part of the file with solely two strains? That’s not a typo. It is going to be used to display how you can deal with lacking information parts, which is a not-too-uncommon downside that appears to crop up when working with information like this.
Needless to say it’s worthwhile to have some fundamental understanding of what the unique file represents earlier than you may make design choices about what information will be plucked out. Given how the pattern file is meant to characterize particular person worker data, it may be safely assumed that every worker document will be recognized by an SSN (in purple) or a reputation (in inexperienced). With these assumptions, data will be delineated the place there’s a change in SSNs from one line to the subsequent.
As this instance is meant to characterize cost info, one may lookup additional info on every document throughout the ERP and doubtlessly conclude that the numbers highlighted in yellow could characterize the sum of money in a month that the enterprise paid to a well being insurer, and the orange quantity is the full quantity.
Granted that I simply made up numbers for this instance, these numbers should not supposed to characterize any practical sum of money.
With that in thoughts, please additionally word that, per the US Social Safety Administration, any Social Safety Quantity that has 00 within the center, or 0000 on the finish, is invalid. This Python programming tutorial will use such representations of Social Safety Numbers for testing functions.
Learn: A Easy Information to File Dealing with in Python
The Objective of Parsing and Extracting Information
Because the introduction states, it might be good to have the values above in an easier-to-use format, akin to a CSV file. Nevertheless, as soon as the items of data are plucked out, they are often saved in any type of structured information file, akin to an XML file. Nevertheless, most end-users who’ve a necessity to look at this info would use a software like Microsoft Excel or the Numbers App that’s bundled in Mac OSX to carry out such evaluation.
For the needs of this text, the purpose is to simply characterize the knowledge above in a CSV file that incorporates strains that observe the format under:
SSN,Final Title,First Title,Month-to-month Quantity,Yearly Quantity
Figuring out the Information Construction for String Processing Utilizing Python
As a way to use string processing instruments in virtually any programming language, it is very important know the place every of the highlighted containers above begins and what number of characters in size the textual content literal is. Textual content editors akin to Notepad++ for Home windows or BBEdit for Mac OSX have built-in performance which will help you to find the beginning positions and sizes of every literal. Observe that each the BBEdit window and Notepad++ window are shrunk for the needs of this instance:

Figuring out positions and lengths utilizing BBEdit
The determine under exhibits how Notepad++ will give the identical info, though the choice size doesn’t seem till the textual content is definitely chosen:

Figuring out positions utilizing Notepad++
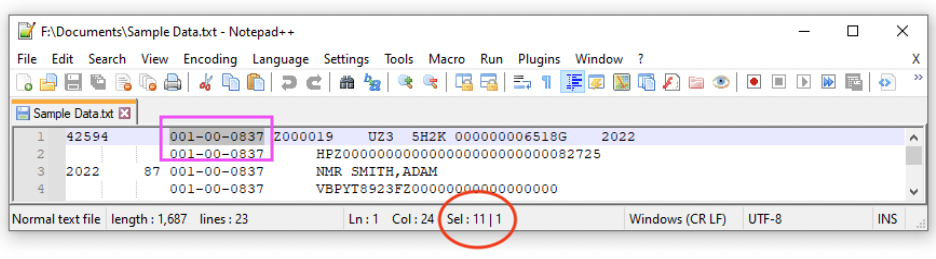
Figuring out the string literal size utilizing Notepad++
Within the instance above, the SSN begins at place 13, assuming a 1-index for the character place ranging from the left. This may be decided by inserting the cursor on the leftmost facet of the road, on this case, earlier than the 4 in 42594, and seeing that this place is 1. Shifting the cursor to the beginning of the SSN will get you to character place 13, as proven within the info within the pink circle on the left. The mouse or Shift-Arrow can be utilized to pick out the entire of the SSN, however not any trailing areas that precede or observe it. BBEdit then supplies the size of the chosen textual content, particularly 11 characters, together with the hyphens.
An essential word: when figuring out the positions and lengths of string literals, be sure that no areas or extraneous characters to the left or proper of the textual content is chosen, as it will yield incorrect values.
Armed with this info, we will decide that for a given document, SSNs can begin at place 13 and prolong for 11 characters. Utilizing the identical strategies, the identical info will be decided for the opposite objects, albeit with some caveats.
|
Report Elements |
Spotlight Coloration |
Beginning Place (1-index) |
String Size |
|
SSN |
Purple |
13 |
11 |
|
Nonsense Month-to-month Quantity |
Yellow |
52 |
6 |
|
Nonsense Yearly Quantity |
Orange |
58 |
5 |
|
Final Title and First Title |
Inexperienced |
34 |
Varies, however can go to the tip of the road. |
Conclusion to Half One in every of Textual content Extraction in Python
Now that now we have recognized the underlying information construction of the textual content we wish to parse and extract, we will transfer on to the precise Python code we’ll use to scrape the information from a file. For brevity’s sake, we’ll cowl that code in a follow-up article: Extracting Textual content in Python.
Learn extra Python programming and software program improvement tutorials.