{kind=link}
[ad_1]
In the course of the current years, there was a shift from monolithic to the microservices structure. The microservices structure makes functions simpler to scale and faster to develop, enabling innovation and accelerating time to marketplace for new options. Nonetheless, this method causes information to dwell in several silos, which makes it tough to carry out analytics. To achieve deeper and richer insights, it’s best to deliver all of your information from totally different silos into one place.
AWS affords replication instruments resembling AWS Database Migration Service (AWS DMS) to copy information modifications from a wide range of supply databases to numerous locations together with Amazon Easy Storage Service (Amazon S3). However prospects who must sync the info in an information lake with updates and deletes on the supply methods nonetheless face just a few challenges:
- It’s tough to use record-level updates or deletes when information are saved in open information format information (resembling JSON, ORC, or Parquet) on Amazon S3.
- In streaming use instances, the place jobs want to jot down information with low latency, row-based codecs resembling JSON and Avro are greatest suited. Nonetheless, scanning many small information with these codecs degrades the learn question efficiency.
- In use instances the place the schema of the supply information modifications steadily, sustaining the schema of the goal datasets by way of customized code is tough and error-prone.
Apache Hudi supplies a great way to resolve these challenges. Hudi builds indexes when it writes the information for the primary time. Hudi makes use of these indexes to find the information to which an replace (or delete) belongs. This allows Hudi to carry out quick upsert (or delete) operations by avoiding the necessity to scan the entire dataset. Hudi supplies two desk varieties, every optimized for sure situations:
- Copy-On-Write (COW) – These tables are frequent for batch processing. On this kind, information is saved in a columnar format (Parquet), and every replace (or delete) creates a brand new model of information through the write.
- Merge-On-Learn (MOR) – Shops Knowledge utilizing a mixture of columnar (for instance Parquet) and row-based (for instance Avro) file codecs and is meant to show near-real time information.
Hudi datasets saved in Amazon S3 present native integration with different AWS providers. For instance, you’ll be able to write Apache Hudi tables utilizing AWS Glue (see Writing to Apache Hudi tables utilizing AWS Glue Customized Connector) or Amazon EMR (see New options from Apache Hudi out there in Amazon EMR). These approaches require having a deep understanding of Hudi’s Spark APIs and programming abilities to construct and keep information pipelines.
On this put up, I present you a special approach of working with streaming information with minimal coding. The steps on this put up exhibit easy methods to construct absolutely scalable pipelines utilizing SQL language with out prior information of Flink or Hudi. You may question and discover your information in a number of information streams by writing acquainted SELECT queries. You may be part of the info from a number of streams and materialize the consequence to a Hudi dataset on Amazon S3.
Resolution overview
The next diagram supplies an general structure of the answer described on this put up. I describe the parts and steps absolutely within the sections that observe.

You employ an Amazon Aurora MySQL database because the supply and a Debezium MySQL connector with the setup described within the MSK Join lab because the change information seize (CDC) replicator. This lab walks you thru the steps to arrange the stack for replicating an Aurora database salesdb to an Amazon Managed Streaming for Apache Kafka (Amazon MSK) cluster, utilizing Amazon MSK Join with a MySql Debezium supply Kafka connector.
In September 2021, AWS introduced MSK Join for working absolutely managed Kafka Join clusters. With just a few clicks, MSK Join lets you simply deploy, monitor, and scale connectors that transfer information out and in of Apache Kafka and MSK clusters from exterior methods resembling databases, file methods, and search indexes. Now you can use MSK Join for constructing a full CDC pipeline from many database sources to your MSK cluster.
Amazon MSK is a totally managed service that makes it straightforward to construct and run functions that use Apache Kafka to course of streaming information. Once you use Apache Kafka, you seize real-time information from sources resembling database change occasions or web site clickstreams. You then construct pipelines (utilizing stream processing frameworks resembling Apache Flink) to ship them to locations resembling a persistent storage or Amazon S3.
Apache Flink is a well-liked framework for constructing stateful streaming and batch pipelines. Flink comes with totally different ranges of abstractions to cowl a broad vary of use instances. See Flink Ideas for extra data.
Flink additionally affords totally different deployment modes relying on which useful resource supplier you select (Hadoop YARN, Kubernetes, or standalone). See Deployment for extra data.
On this put up, you employ the SQL Consumer instrument as an interactive approach of authoring Flink jobs in SQL syntax. sql-client.sh compiles and submits jobs to a long-running Flink cluster (session mode) on Amazon EMR. Relying on the script, sql-client.sh both exhibits the tabular formatted output of the job in actual time, or returns a job ID for long-running jobs.
You implement the answer with the next high-level steps:
- Create an EMR cluster.
- Configure Flink with Kafka and Hudi desk connectors.
- Develop your real-time extract, remodel, and cargo (ETL) job.
- Deploy your pipeline to manufacturing.
Conditions
This put up assumes you could have a working MSK Join stack in your atmosphere with the next parts:
- Aurora MySQL internet hosting a database. On this put up, you employ the instance database
salesdb. - The Debezium MySQL connector working on MSK Join, ending in Amazon MSK in your Amazon Digital Personal Cloud (Amazon VPC).
- An MSK cluster working inside in a VPC.
In case you don’t have an MSK Join stack, observe the directions within the MSK Join lab setup and confirm that your supply connector replicates information modifications to the MSK subjects.
You additionally want the flexibility to attach on to the EMR chief node. Session Supervisor is a function of AWS Programs Supervisor that gives you with an interactive one-click browser-based shell window. Session Supervisor additionally lets you adjust to company insurance policies that require managed entry to managed nodes. See Establishing Session Supervisor to discover ways to connect with your managed nodes in your account by way of this methodology.
If Session Supervisor isn’t an choice, you too can use Amazon Elastic Compute Cloud (Amazon EC2) non-public key pairs, however you’ll must launch the cluster in a public subnet and supply inbound SSH entry. See Hook up with the grasp node utilizing SSH for extra data.
Create an EMR cluster
The most recent launched model of Apache Hudi is 0.10.0, on the time of writing. Hudi launch model 0.10.0 is suitable with Flink launch model 1.13. You want Amazon EMR launch model emr-6.4.0 and later, which comes with Flink launch model 1.13. To launch a cluster with Flink put in utilizing the AWS Command Line Interface (AWS CLI), full the next steps:
- Create a file,
configurations.json, with the next content material: - Create an EMR cluster in a personal subnet (advisable) or in a public subnet of the identical VPC as the place you host your MSK cluster. Enter a reputation to your cluster with the
--namechoice, and specify the title of your EC2 key pair in addition to the subnet ID with the--ec2-attributeschoice. See the next code: - Wait till the cluster state modifications to
Working. - Retrieve the DNS title of the chief node utilizing both the Amazon EMR console or the AWS CLI.
- Hook up with the chief node by way of Session Supervisor or utilizing SSH and an EC2 non-public key on Linux, Unix, and Mac OS X.
- When connecting utilizing SSH, port 22 should be allowed by the chief node’s safety group.
- Make sure that the MSK cluster’s safety group has an inbound guidelines that accepts site visitors from the EMR cluster’s safety teams.
Configure Flink with Kafka and Hudi desk connectors
Flink desk connectors help you connect with exterior methods when programming your stream operations utilizing Desk APIs. Supply connectors present entry to streaming providers together with Kinesis or Apache Kafka as an information supply. Sink connectors permit Flink to emit stream processing outcomes to exterior methods or storage providers like Amazon S3.
In your Amazon EMR chief node, obtain the next connectors and save them within the /lib/flink/lib listing:
- Supply connector – Obtain flink-connector-kafka_2.11-1.13.1.jar from the Apache repository. The Apache Kafka SQL connector permits Flink to learn information from Kafka subjects.
- Sink connector – Amazon EMR launch model emr-6.4.0 comes with Hudi launch model 0.8.0. Nonetheless, on this put up you want Hudi Flink bundle connector launch model 0.10.0, which is suitable with Flink launch model 1.13. Obtain hudi-flink-bundle_2.11-0.10.0.jar from the Apache repository. It additionally incorporates a number of file system purchasers, together with S3A for integrating with Amazon S3.
Develop your real-time ETL job
On this put up, you employ the Debezium supply Kafka connector to stream information modifications of a pattern database, salesdb, to your MSK cluster. Your connector produces information modifications in JSON. See Debezium Occasion Deserialization for extra particulars. The Flink Kafka connector can deserialize occasions in JSON format by setting worth.format with debezium-json within the desk choices. This configuration supplies the complete assist for information updates and deletes, along with inserts.
You construct a brand new job utilizing Flink SQL APIs. These APIs help you work with the streaming information, much like tables in relational databases. SQL queries specified on this methodology run constantly over the info occasions within the supply stream. As a result of the Flink utility consumes unbounded information from a stream, the output continually modifications. To ship the output to a different system, Flink emits replace or delete occasions to the downstream sink operators. Due to this fact, whenever you work with CDC information or write SQL queries the place the output rows must replace or delete, it’s essential to present a sink connector that helps these actions. In any other case, the Flink job ends with an error with the next message:
Launch the Flink SQL consumer
Begin a Flink YARN utility in your EMR cluster with the configurations you beforehand specified within the configurations.json file:
After the command runs efficiently, you’re prepared to jot down your first job. Run the next command to launch sql-client:
Your terminal window seems like the next screenshot.

Set the job parameters
Run the next command to set the checkpointing interval for this session:
Outline your supply tables
Conceptually, processing streams utilizing SQL queries requires decoding the occasions as logical information in a desk. Due to this fact, step one earlier than studying or writing the info with SQL APIs is to create supply and goal tables. The desk definition contains the connection settings and configuration together with a schema that defines the construction and the serialization format of the objects within the stream.
On this put up, you create three supply tables. Every corresponds to a subject in Amazon MSK. You additionally create a single goal desk that writes the output information information to a Hudi dataset saved on Amazon S3.
Change BOOTSTRAP SERVERS ADDRESSES with your personal Amazon MSK cluster data within the 'properties.bootstrap.servers' choice and run the next instructions in your sql-client terminal:
By default, sql-client shops these tables in reminiscence. They solely dwell at some stage in the lively session. Anytime your sql-client session expires, otherwise you exit, you might want to recreate your tables.
Outline the sink desk
The next command creates the goal desk. You specify 'hudi' because the connector on this desk. The remainder of the Hudi configurations are set within the with(…) part of the CREATE TABLE assertion. See the complete checklist of Flink SQL configs to study extra. Change S3URI OF HUDI DATASET LOCATION along with your Hudi dataset location in Amazon S3 and run the next code:
Confirm the Flink job’s outcomes from a number of subjects
For choose queries, sql-client submits the job to a Flink cluster, then shows the outcomes on the display screen in actual time. Run the next choose question to view your Amazon MSK information:
This question joins three streams and aggregates the depend of buyer orders, grouped by every buyer report. After just a few seconds, it’s best to see the lead to your terminal. Be aware how the terminal output modifications because the Flink job consumes extra occasions from the supply streams.
Sink the consequence to a Hudi dataset
To have an entire pipeline, you might want to ship the consequence to a Hudi dataset on Amazon S3. To try this, add an insert into CustomerHudi assertion in entrance of the choose question:
This time, the sql-client disconnects from the cluster after submitting the job. The consumer terminal doesn’t have to attend for the outcomes of the job because it sinks its outcomes to a Hudi dataset. The job continues to run in your Flink cluster even after you cease the sql-client session.
Wait a couple of minutes till the job generates Hudi commit log information to Amazon S3. Then navigate to the situation in Amazon S3 you specified to your CustomerHudi desk, which incorporates a Hudi dataset partitioned by MKTSEGMENT column. Inside every partition you additionally discover Hudi commit log information. It’s because you outlined the desk kind as MERGE_ON_READ. On this mode with the default configurations, Hudi merges commit logs to bigger Parquet information after 5 delta commit logs happen. Consult with Desk & Question Varieties for extra data. You may change this setup by altering the desk kind to COPY_ON_WRITE or specifying your customized compaction configurations.
Question the Hudi dataset
You may additionally use a Hudi Flink connector as a supply connector to learn from a Hudi dataset saved on Amazon S3. You try this by working a choose assertion in opposition to the CustomerHudi desk, or create a brand new desk with hudi specified for connector. The path should level to an current Hudi dataset’s location on Amazon S3. Change S3URI OF HUDI DATASET LOCATION along with your location and run the next command to create a brand new desk:
Be aware the extra column names prefixed with _hoodie_. These columns are added by Hudi through the write to take care of the metadata of every report. Additionally be aware the additional 'hoodie.datasource.question.kind' learn configuration handed within the WITH portion of the desk definition. This makes positive you learn from the real-time view of your Hudi dataset. Run the next command:
The terminal shows the consequence inside 30 seconds. Navigate to the Flink internet interface, the place you’ll be able to observe a brand new Flink job began by the choose question (See under for easy methods to discover the Flink internet interface). It scans the dedicated information within the Hudi dataset and returns the consequence to the Flink SQL consumer.
Use a mysql CLI or your most well-liked IDE to connect with your salesdb database, which is hosted on Aurora MySQL. Run just a few insert statements in opposition to the SALES_ORDER_ALL desk:
After just a few seconds, a brand new commit log file seems in your Hudi dataset on Amazon S3. The Debezium for MySQL Kafka connector captures the modifications and produces occasions to the MSK matter. The Flink utility consumes the brand new occasions from the subject and updates the customer_count column accordingly. It then sends the modified information to the Hudi connector for merging with the Hudi dataset.
Hudi helps totally different write operation varieties. The default operation is upsert, the place it initially inserts the information within the dataset. When a report with an current key arrives in a course of, it’s handled as an replace. This operation is beneficial right here the place you anticipate to sync your dataset with the supply database, and duplicate information are usually not anticipated.
Discover the Flink internet interface
The Flink internet interface helps you view a Flink job’s configuration, graph, standing, exception errors, useful resource utilization, and extra. To entry it, first you might want to arrange an SSH tunnel and activate a proxy in your browser, to connect with the YARN Useful resource Supervisor. After you connect with the Useful resource Supervisor, you select the YARN utility that’s internet hosting your Flink session. Select the hyperlink below the Monitoring UI column to navigate to the Flink internet interface. For extra data, see Discovering the Flink internet interface.
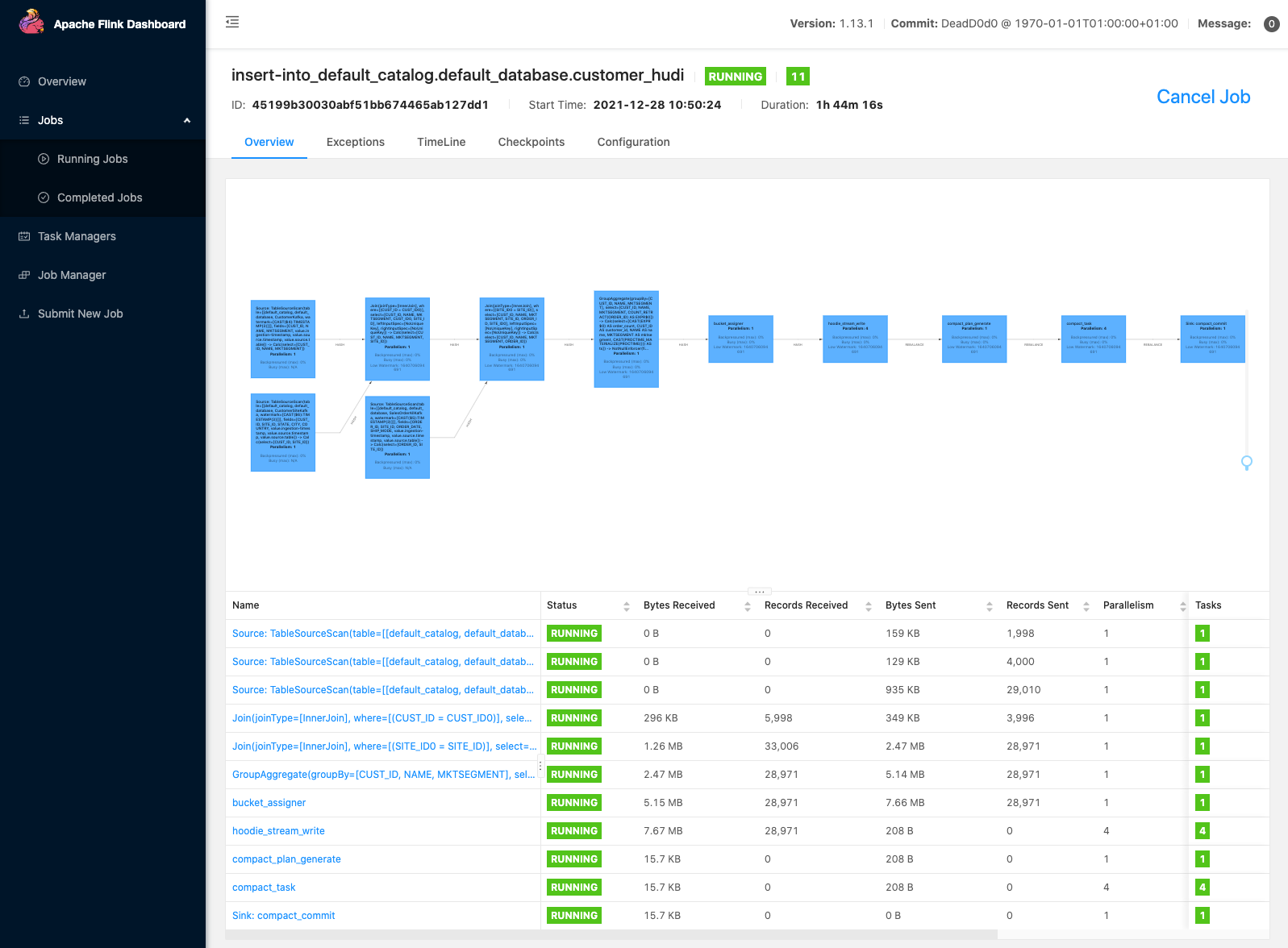
Deploy your pipeline to manufacturing
I like to recommend utilizing Flink sql-client for rapidly constructing information pipelines in an interactive approach. It’s a sensible choice for experiments, growth, or testing your information pipelines. For manufacturing environments, nevertheless, I like to recommend embedding your SQL scripts in a Flink Java utility and working it on Amazon Kinesis Knowledge Analytics. Kinesis Knowledge Analytics is a totally managed service for working Flink functions; it has built-in auto scaling and fault tolerance options to supply your manufacturing functions the supply and scalability they want. A Flink Hudi utility with the scripts from this this put up is out there on GitHub. I encourage you to go to this repo, and examine the variations between working in sql-client and Kinesis Knowledge Analytics.
Clear up
To keep away from incurring ongoing fees, full the next cleanup steps:
- Cease the EMR cluster.
- Delete the AWS CloudFormation stack you created utilizing the MSK Join Lab setup.
Conclusion
Constructing an information lake is step one to interrupt down information silos and working analytics to realize insights from all of your information. Syncing the info between the transactional databases and information information on an information lake isn’t trivial and entails vital effort. Earlier than Hudi added assist for Flink SQL APIs, Hudi prospects needed to have the mandatory abilities for writing Apache Spark code and working it on AWS Glue or Amazon EMR. On this put up, I confirmed you a brand new approach in which you’ll be able to interactively discover your information in streaming providers utilizing SQL queries, and speed up the event course of to your information pipelines.
To study extra, go to Hudi on Amazon EMR documentation.
In regards to the Writer
 Ali Alemi is a Streaming Specialist Options Architect at AWS. Ali advises AWS prospects with architectural greatest practices and helps them design real-time analytics information methods that are dependable, safe, environment friendly, and cost-effective. He works backward from buyer’s use instances and designs information options to resolve their enterprise issues. Previous to becoming a member of AWS, Ali supported a number of public sector prospects and AWS consulting companions of their utility modernization journey and migration to the Cloud.
Ali Alemi is a Streaming Specialist Options Architect at AWS. Ali advises AWS prospects with architectural greatest practices and helps them design real-time analytics information methods that are dependable, safe, environment friendly, and cost-effective. He works backward from buyer’s use instances and designs information options to resolve their enterprise issues. Previous to becoming a member of AWS, Ali supported a number of public sector prospects and AWS consulting companions of their utility modernization journey and migration to the Cloud.
[ad_2]