
{kind=link}
[ad_1]
Due to “Bundlegate”, it’s been a wild couple of weeks. Right here’s what occurred and the place I feel we’re going.
It’s been a wild couple of weeks in Information Twitter with one other new scorching debate.
As I lay tossing and handing over mattress, fascinated about the way forward for the trendy knowledge stack, I couldn’t assist really feel the strain to put in writing yet one more opinion piece 😉
What really occurred?
When you have been MIA, Gorkem Yurtseven kickstarted this debate with an article referred to as “The Unbundling of Airflow”.
He defined that after small merchandise develop into giant platforms, they’re ripe for unbundling, or having its part capabilities abstracted into small, extra targeted merchandise. Craigslist is a superb instance — its Neighborhood part has been taken over by Nextdoor, Personals by Tinder, Dialogue Boards by Reddit, For Sale by OfferUp, and so forth.
Gorkem argued that within the knowledge world, the identical factor is occurring with Airflow.
Earlier than the fragmentation of the info stack, it wasn’t unusual to create end-to-end pipelines with Airflow. Organizations used to construct virtually total knowledge workflows as customized scripts developed by in-house knowledge engineers. Greater corporations even constructed their very own frameworks inside Airflow, for instance, frameworks with dbt-like performance for SQL transformations with a purpose to make it simpler for knowledge analysts to put in writing these pipelines.
At the moment, knowledge practitioners have many instruments below their belt and solely very hardly ever they’ve to succeed in for a instrument like Airflow… If the unbundling of Airflow means all of the heavy lifting is finished by separate instruments, what’s left behind?
Gorkem Yurtseven
As one of many knowledge groups again within the day that ended up constructing our personal dbt-like performance for transformations in R and Python, Gorkem’s phrases hit dwelling.
Airflow’s functions have been constructed into ingestion instruments (Airbyte, Fivetran, and Meltano), transformation layers (dbt), reverse ETL (Hightouch and Census), and extra.
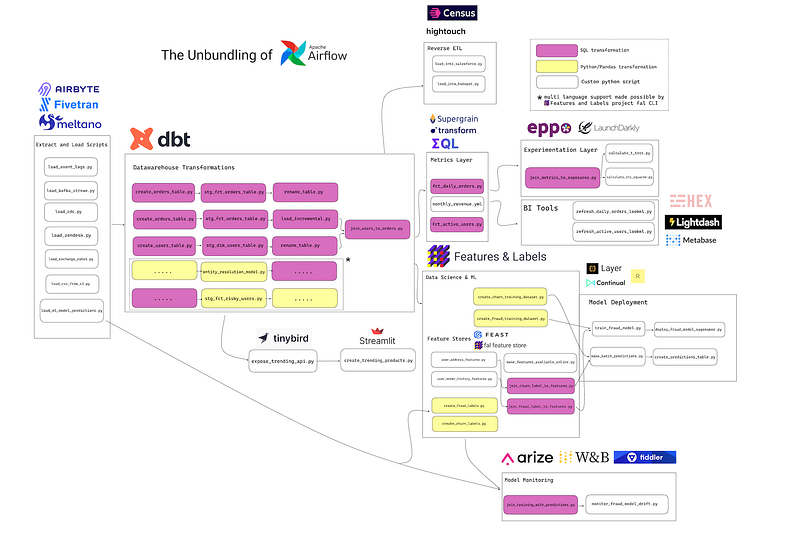
Sadly, this has led to a loopy quantity of fragmentation within the knowledge stack. I joke about this rather a lot, however truthfully I really feel horrible for somebody shopping for knowledge know-how proper now. The fragmentation and overlaps are mind-blowing for even an insider like me to totally grasp.
Nick Schrock from Elementl wrote a response on Dagster’s weblog titled the “Rebundling of the Information Platform” that broke the info neighborhood… once more. He agreed with Gorkem that the info stack was being unbundled, and mentioned that this unbundling was creating its personal set of issues.
I don’t assume anybody believes that this is a perfect finish state. The submit itself advocates for consolidation. Having this many instruments and not using a coherent, centralized management aircraft is lunacy, and a horrible endstate for knowledge practitioners and their stakeholders… And but, that is the truth we’re slouching towards on this “unbundled” world.
Nick Schrock
Then, whereas I used to be writing this text, Ananth Packkildurai chimed in on the controversy — first with a tweet after which with the newest challenge of his Information Engineering Weekly publication.
Ananth agreed with the concept that unbundling has occurred, however tied it to a bigger challenge. As knowledge groups and firms have grown, knowledge has develop into extra advanced and knowledge orchestration, high quality, lineage, and mannequin administration have develop into important issues.
The info stack unbundled to resolve these particular issues, which simply resulted in siloed, “duct tape techniques”.
The info neighborhood typically compares the trendy tech stack with the Unix philosophy. Nonetheless, we’re lacking the working system for the info. We have to merge each the mannequin and job execution unit into one unit. In any other case, any abstraction we construct with out the unification will additional amplify the disorganization of the info. The info as an asset will stay an aspirational aim.
Ananth Packkildurai
So… what’s my take? The place are we headed?
There are two varieties of individuals within the knowledge world — those that imagine in bundling and those that assume unbundling is the long run.
I imagine that the reply lies someplace within the center. Listed below are a few of my predictions and takes.
1. There’ll completely be extra bundling from our present model of the trendy knowledge stack.
The present model of the trendy knowledge stack, with a brand new firm launching each 45 minutes, is unsustainable. We’re completely in the course of the golden period of innovation within the MDS, funded fairly generously by Enterprise Capital $$ — all in seek for the subsequent Snowflake. I’ve heard tales of completely completely happy (knowledge) product managers in FAANG corporations being handed thousands and thousands of {dollars} to “check out any concept”.
This euphoria has had huge benefits. A ton of good individuals are fixing knowledge groups’ greatest tooling challenges. Their work has made the trendy knowledge stack a factor. It has made the “knowledge operate” extra mainstream. And, most significantly, it has spurred innovation.
However, truthfully, this gained’t final without end. The money will dry up. Consolidation, mergers, and acquisitions will occur. (We’ve already began seeing glimpses of this with dbt’s transfer into the metrics layer and Hevo’s transfer to introduce reverse ETL together with their knowledge ingestion product.) Most significantly, prospects will begin demanding much less complexity as they make selections about their knowledge stack. That is the place bundling will begin to win.
2. Nonetheless, we by no means will (and shouldn’t ever) have a totally bundled knowledge stack.
Imagine it or not, the info world began off with the imaginative and prescient of a totally bundled knowledge stack. A decade in the past, corporations like RJ Metrics and Domo aimed to create their very own holistic knowledge platforms.
The problem with a totally bundled stack is that sources are at all times restricted and innovation stalls. This hole will create a possibility for unbundling, and so I imagine we’ll undergo cycles of bundling and unbundling. That being mentioned, I imagine that the info area particularly has peculiarities that make it tough for bundled platforms to really win.
My co-founder Varun and I spend a ton of time fascinated about the DNA of corporations or merchandise. We predict it’s vital — maybe crucial factor that defines who succeeds in a class of product.
Let’s take a look at the cloud battles. AWS, for instance, has at all times been largely targeted on scale —one thing they do an awesome job in. Then again, Azure coming from Microsoft has at all times had a extra end-user-focused DNA, stemming from its MS Workplace days. It’s no shock that AWS doesn’t do as nicely in creating world-class, consumer expertise–targeted functions as Azure, whereas Azure doesn’t do as nicely in scaling technical workloads as AWS.
Earlier than we are able to discuss concerning the DNA of the info world, we now have to acknowledge that its sheer variety. The people of knowledge are knowledge engineers, analysts, analytics engineers, scientists, product managers, enterprise analysts, citizen scientists, and extra. Every of those individuals has their very own favourite and equally various knowledge instruments, the whole lot from SQL, Looker, and Jupyter to Python, Tableau, dbt, and R. And knowledge initiatives have their very own technical necessities and peculiarities — some want real-time processing whereas some want velocity for ad-hoc evaluation, resulting in a complete host of knowledge infrastructure applied sciences (warehouses, lakehouses, and the whole lot in between).
Due to this variety, the know-how for every of those totally different personas and use instances every can have very totally different DNA. For instance, an organization constructing BI needs to be targeted on the end-user expertise, whereas firm constructing a knowledge warehouse needs to be targeted on reliability and scaling.
For this reason I imagine that whereas bundling will occur, it should solely occur in areas the place merchandise’ elementary DNA is analogous. For instance, we are going to probably see knowledge high quality merge with knowledge transformation, and doubtlessly knowledge ingestion merge with reverse ETL. Nonetheless, we in all probability gained’t see knowledge high quality bundled with reverse ETL.
3. Metadata holds the important thing to unlocking concord in a various knowledge stack.
Whereas we’ll see extra consolidation, the basic variety of knowledge and the people of knowledge isn’t going away. There’ll at all times be use instances the place Python is best than SQL or real-time processing is best than batch, and vice versa.
When you perceive this elementary actuality, you must cease trying to find a future with a common “bundled knowledge platform” that works for everybody — and as an alternative discover methods for the various components of our unbundled knowledge stack to work collectively, in excellent concord.
Information is chaos. That doesn’t imply that work must be.
I imagine that the important thing to serving to our knowledge stack work collectively is in activating metadata. We’ve solely scratched the floor of what metadata can do for us, however utilizing metadata to its fullest potential can basically change how our knowledge techniques function.
At the moment, metadata is used for (comparatively) simplistic use instances like knowledge discovery and knowledge catalogs. We take a bunch of metadata from a bunch of instruments and put it right into a instrument we name the info catalog or the info governance instrument. The issue with this strategy is that it mainly provides yet another siloed instrument to an already siloed knowledge stack.
As a substitute, take a second and picture what a world may appear to be in the event you may have a Section or Zapier-like expertise within the trendy knowledge stack — the place metadata can create concord throughout all our instruments and energy excellent experiences.
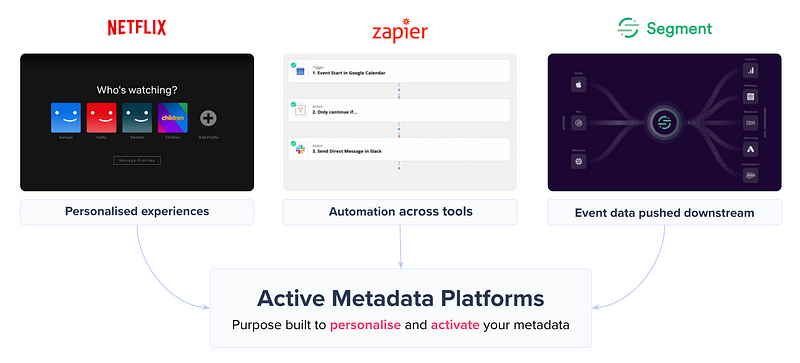
For instance, one use case for metadata activation might be so simple as notifying downstream shoppers of upstream modifications.
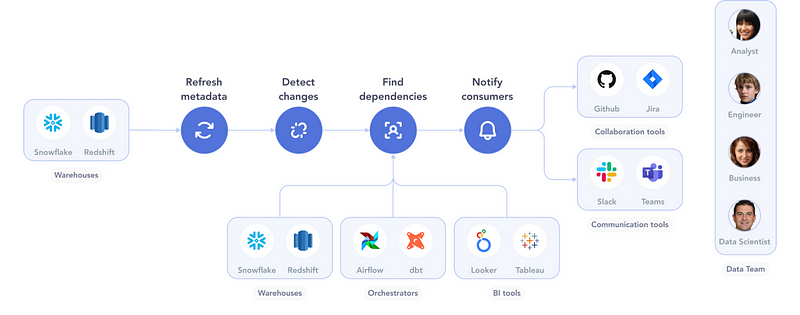
A Zap-like workflow for this easy course of may appear to be this:
When a knowledge retailer modifications…
- Refresh metadata: Crawl the info retailer to retrieve its up to date metadata.
- Detect modifications: Evaluate the brand new metadata in opposition to the earlier metadata. Determine any modifications that might trigger an influence — including or eradicating columns, for instance.
- Discover dependencies: Use lineage to search out customers of the info retailer. These may embody transformation processes, different knowledge shops, BI dashboards, and so forth.
- Notify shoppers: Notify every client by way of their most well-liked communication channel — Slack, Jira, and many others.
This workflow is also included as a part of the testing phases of adjusting a knowledge retailer. For instance, the CI/CD course of that modifications the info retailer may additionally set off this workflow. Orchestration can then notify shoppers earlier than manufacturing techniques change.
In Stephen Bailey’s phrases, “Nobody is aware of what the info stack will appear to be in ten years, however I can assure you this: metadata would be the glue.”
I feel this debate is way from over, nevertheless it’s superb what number of insights and scorching takes (like this one) that it has stirred up.
To maintain the dialogue going, we’re internet hosting Gorkem Yurtseven, Nick Schrock, and Ananth Packkildurai for our Nice Information Debate on Tuesday, 15 March.
Join the digital occasion right here: https://atlan.com/great-data-debate/
Header picture: Bakhrom Tursunov on Unsplash
[ad_2]