
{kind=link}
[ad_1]
Introduction
This weblog is a component one among our Admin Necessities collection, the place we’ll concentrate on subjects which are vital to these managing and sustaining Databricks environments. Preserve an eye fixed out for extra blogs on information governance, ops & automation, consumer administration & accessibility, and value monitoring & administration within the close to future!
In 2020, Databricks started releasing personal previews of a number of platform options identified collectively as Enterprise 2.0 (or E2); these options supplied the subsequent iteration of the Lakehouse platform, creating the scalability and safety to match the ability and velocity already out there on Databricks. When Enterprise 2.0 was made publicly out there, one of the anticipated additions was the flexibility to create a number of workspaces from a single account. This characteristic opened new prospects for collaboration, organizational alignment, and simplification. As now we have discovered since, nevertheless, it has additionally raised a number of questions. Based mostly on our expertise throughout enterprise prospects of each measurement, form and vertical, this weblog will lay out solutions and greatest practices to the most typical questions round workspace administration inside Databricks; at a basic stage, this boils right down to a easy query: precisely when ought to a brand new workspace be created? Particularly, we’ll spotlight the important thing methods for organizing your workspaces, and greatest practices of every.
Workspace group fundamentals
Though every cloud supplier (AWS, Azure and GCP) has a unique underlying structure, the group of Databricks workspaces throughout clouds is comparable. The logical prime stage assemble is an E2 grasp account (AWS) or a subscription object (Azure Databricks/GCP). In AWS, we provision a single E2 account per group that gives a unified pane of visibility and management to all workspaces. On this method, your admin exercise is centralized, with the flexibility to allow SSO, Audit Logs, and Unity Catalog. Azure has comparatively much less restriction on creation of top-level subscription objects; nevertheless, we nonetheless advocate that the variety of top-level subscriptions used to create Databricks workspaces be managed as a lot as doable. We’ll check with the top-level assemble as an account all through this weblog, whether or not it’s an AWS E2 account or GCP/Azure subscription.
Inside a top-level account, a number of workspaces could be created. The advisable max workspaces per account is between 20 and 50 on Azure, with a exhausting restrict on AWS. This restrict arises from the executive overhead that stems from a rising variety of workspaces: managing collaboration, entry, and safety throughout a whole lot of workspaces can turn out to be an especially troublesome activity, even with distinctive automation processes. Under, we current a high-level object mannequin of a Databricks account.
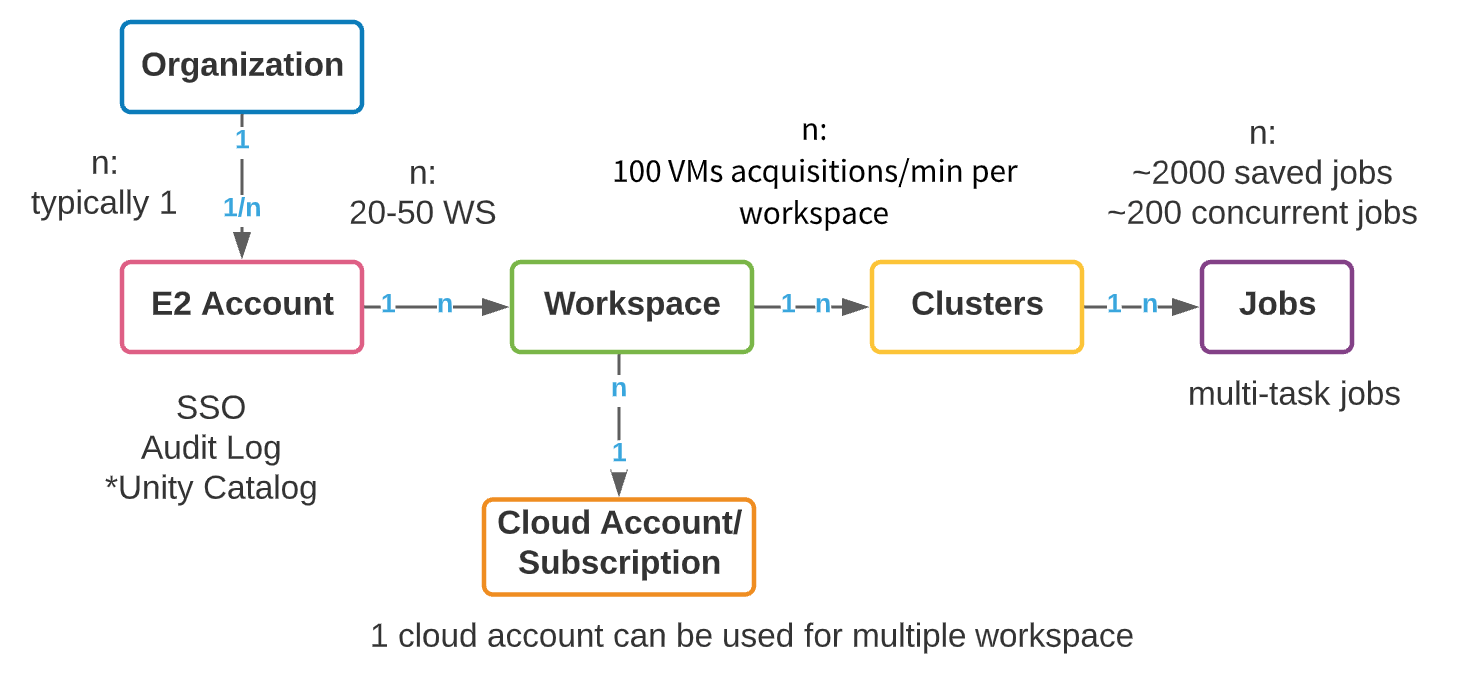
Enterprises must create assets of their cloud account to help multi-tenancy necessities. The creation of separate cloud accounts and workspaces for every new use case does have some clear benefits: ease of value monitoring, information and consumer isolation, and a smaller blast radius in case of safety incidents. Nonetheless, account proliferation brings with it a separate set of complexities – governance, metadata administration and collaboration overhead develop together with the variety of accounts. The important thing, in fact, is steadiness. Under, we’ll first undergo some basic concerns for enterprise workspace group; then, we’ll undergo two frequent workspace isolation methods that we see amongst our prospects: LOB-based and product-based. Every has strengths, weaknesses and complexities that we are going to talk about earlier than giving greatest practices.
Common workspace group concerns
When designing your workspace technique, the very first thing we frequently see prospects leap to is the macro-level organizational selections; nevertheless, there are numerous lower-level choices which are simply as vital! We’ve compiled probably the most pertinent of those beneath.
A easy three-workspace strategy
Though we spend most of this weblog speaking about the best way to cut up your workspaces for max effectiveness, there are a complete class of Databricks prospects for whom a single, unified workspace per surroundings is greater than sufficient! In truth, this has turn out to be increasingly more sensible with the rise of options like Repos, Unity Catalog, persona-based touchdown pages, and so forth. In such circumstances, we nonetheless advocate the separation of Improvement, Staging and Manufacturing workspaces for validation and QA functions. This creates an surroundings preferrred for small companies or groups that worth agility over complexity.
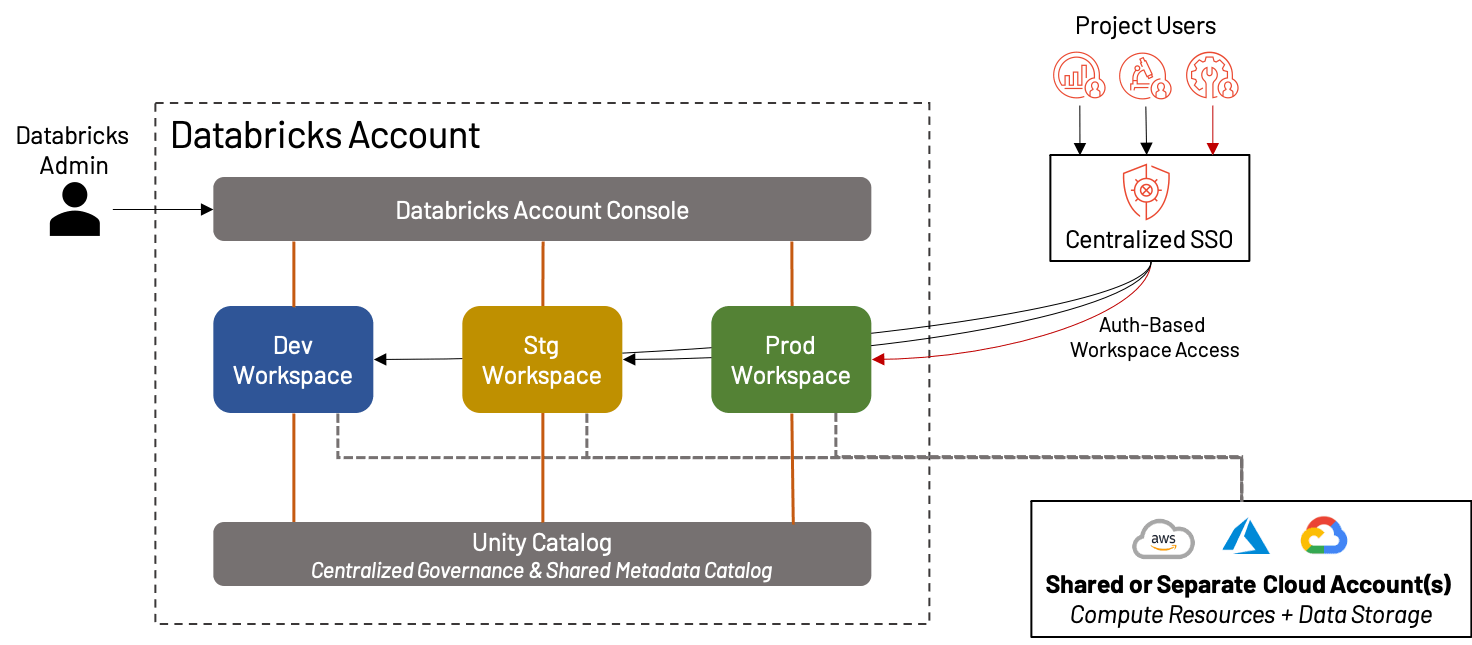
The advantages and disadvantages of making a single set of workspaces are:
+ There isn’t any concern of cluttering the workspace internally, mixing belongings, or diluting the price/utilization throughout a number of tasks/groups; all the pieces is in the identical surroundings
+ Simplicity of group means diminished administrative overhead
– For bigger organizations, a single dev/stg/prd workspace is untenable attributable to platform limits, litter, incapability to isolate information, and governance considerations
If a single set of workspaces looks like the proper strategy for you, the next greatest practices will assist preserve your Lakehouse working easily:
- Outline a standardized course of for pushing code between the assorted environments; as a result of there is just one set of environments, this can be easier than with different approaches. Leverage options resembling Repos and Secrets and techniques and exterior instruments that foster good CI/CD processes to verify your transitions happen mechanically and easily.
- Set up and frequently assessment Id Supplier teams which are mapped to Databricks belongings; as a result of these teams are the first driver of consumer authorization on this technique, it’s essential that they be correct, and that they map to the suitable underlying information and compute assets. For instance, most customers probably don’t want entry to the manufacturing workspace; solely a small handful of engineers or admins might have the permissions.
- Keep watch over your utilization and know the Databricks Useful resource Limits; in case your workspace utilization or consumer depend begins to develop, chances are you’ll want to think about adopting a extra concerned workspace group technique to keep away from per-workspace limits. Leverage useful resource tagging wherever doable as a way to observe value and utilization metrics.
Leveraging sandbox workspaces
In any of the methods talked about all through this text, a sandbox surroundings is an efficient apply to permit customers to incubate and develop much less formal, however nonetheless doubtlessly invaluable work. Critically, these sandbox environments must steadiness the liberty to discover actual information with safety towards unintentionally (or deliberately) impacting manufacturing workloads. One frequent greatest apply for such workspaces is to host them in a completely separate cloud account; this vastly limits the blast radius of customers within the workspace. On the identical time, establishing easy guardrails (resembling Cluster Insurance policies, limiting the information entry to “play” or cleansed datasets, and shutting down outbound connectivity the place doable) means customers can have relative freedom to do (nearly) no matter they wish to do without having fixed admin supervision. Lastly, inside communication is simply as vital; if customers unwittingly construct an incredible software within the Sandbox that pulls 1000’s of customers, or count on production-level help for his or her work on this surroundings, these administrative financial savings will evaporate rapidly.
Finest practices for sandbox workspaces embrace:
- Use a separate cloud account that doesn’t comprise delicate or manufacturing information.
- Arrange easy guardrails in order that customers can have relative freedom over the surroundings without having admin oversight.
- Talk clearly that the sandbox surroundings is “self-service.”
Information isolation & sensitivity
Delicate information is rising in prominence amongst our prospects in all verticals; information that was as soon as restricted to healthcare suppliers or bank card processors is now turning into supply for understanding affected person evaluation or buyer sentiment, analyzing rising markets, positioning new merchandise, and nearly the rest you’ll be able to consider. This wealth of knowledge comes with excessive potential threat, with ever-increasing threats of knowledge breaches; because of this, conserving delicate information segregated and guarded is vital it doesn’t matter what organizational technique you select. Databricks offers a number of means to shield delicate information (resembling ACLs and safe sharing), and mixed with cloud supplier instruments, could make the Lakehouse you construct as low-risk as doable. Among the greatest practices round Information Isolation & Sensitivity embrace:
- Perceive your distinctive information safety wants; that is a very powerful level. Each enterprise has completely different information, and your information will drive your governance.
- Apply insurance policies and controls at each the storage stage and on the metastore. S3 insurance policies and ADLS ACLs ought to all the time be utilized utilizing the precept of least-access. Leverage Unity Catalog to use an extra layer of management over information entry.
- Separate your delicate information from non-sensitive information each logically and bodily; many shoppers use totally separate cloud accounts (and Databricks workspaces) for delicate and non-sensitive information.
DR and regional backup
Catastrophe Restoration (DR) is a broad matter that’s vital whether or not you employ AWS, Azure or GCP; we gained’t cowl all the pieces on this weblog, however will slightly concentrate on how DR and Regional concerns play into workspace design. On this context, DR implies the creation and upkeep of a workspace in a separate area from the usual Manufacturing workspace.
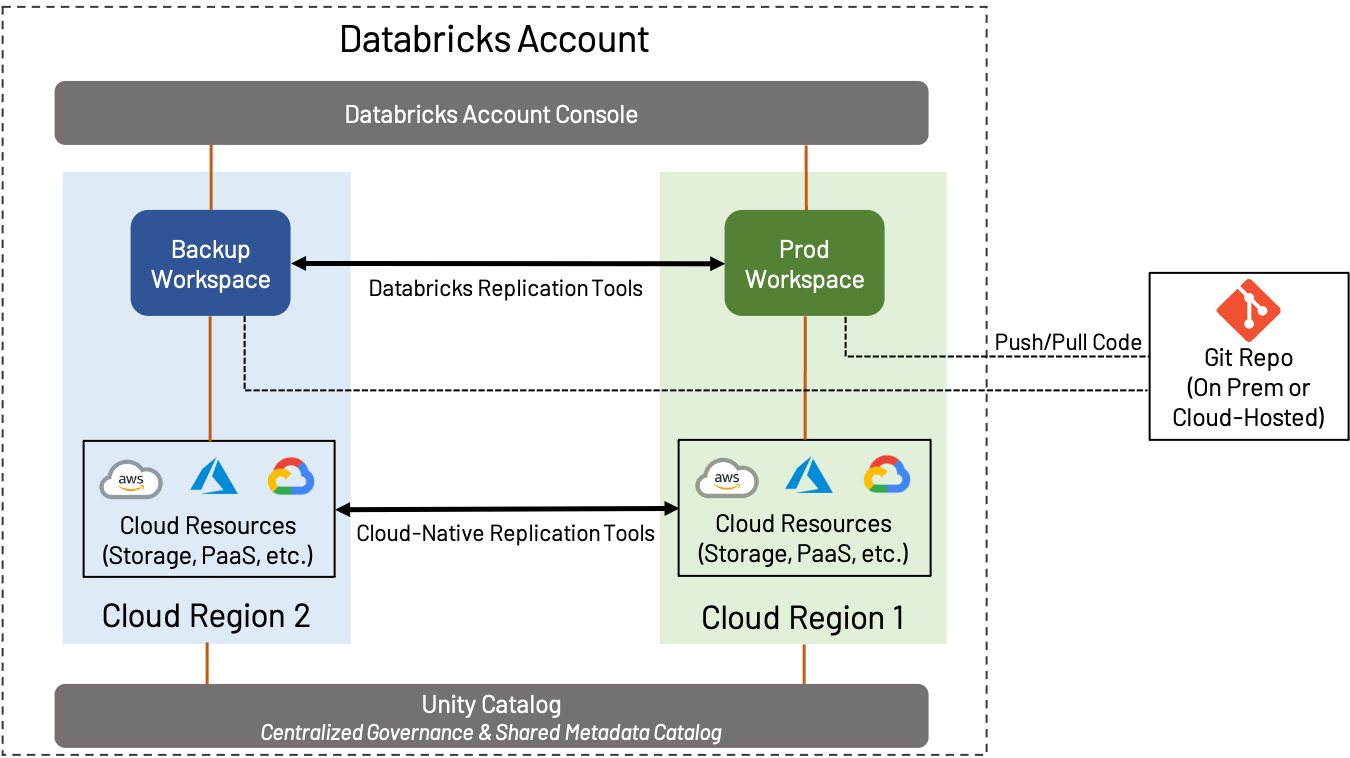
DR technique can range extensively relying on the wants of the enterprise. For instance, some prospects favor to keep up an active-active configuration, the place all belongings from one workspace are continually replicated to a secondary workspace; this offers the utmost quantity of redundancy, but additionally implies complexity and value (continually transferring information cross-region and performing object replication and deduplication is a sophisticated course of). However, some prospects favor to do the minimal needed to make sure enterprise continuity; a secondary workspace might comprise little or no till failover happens, or could also be backed up solely on an occasional foundation. Figuring out the proper stage of failover is essential.
No matter what stage of DR you select to implement, we advocate the next:
- Retailer code in a Git repository of your alternative, both on-prem or within the cloud, and use options resembling Repos to sync it to Databricks wherever doable.
- Every time doable, use Delta Lake along side Deep Clone to copy information; this offers a straightforward, open-source strategy to effectively again up information.
- Use the cloud-native instruments supplied by your cloud supplier to carry out backup of issues resembling information not saved in Delta Lake, exterior databases, configurations, and so forth.
- Use instruments resembling Terraform to again up objects resembling notebooks, jobs, secrets and techniques, clusters, and different workspace objects.
Keep in mind: Databricks is chargeable for sustaining regional workspace infrastructure within the Management Aircraft, however you’re chargeable for your workspace-specific belongings, in addition to the cloud infrastructure your manufacturing jobs depend upon.
Isolation by line of enterprise (LOB)
We now dive into the precise group of workspaces in an enterprise context. LOB-based challenge isolation grows out of the standard enterprise-centric method of IT assets – it additionally carries many conventional strengths (and weaknesses) of LOB-centric alignment. As such, for a lot of massive companies, this strategy to workspace administration will come naturally.
In an LOB-based workspace technique, every purposeful unit of a enterprise will obtain a set of workspaces; historically, this can embrace growth, staging, and manufacturing workspaces, though now we have seen prospects with as much as 10 intermediate levels, every potential with their very own workspace (not advisable)! Code is written and examined in DEV, then promoted (through CI/CD automation) to STG, and eventually lands in PRD, the place it runs as a scheduled job till being deprecated. Setting kind and unbiased LOB are the first causes to provoke a brand new workspace on this mannequin; doing so for each use case or information product could also be extreme.
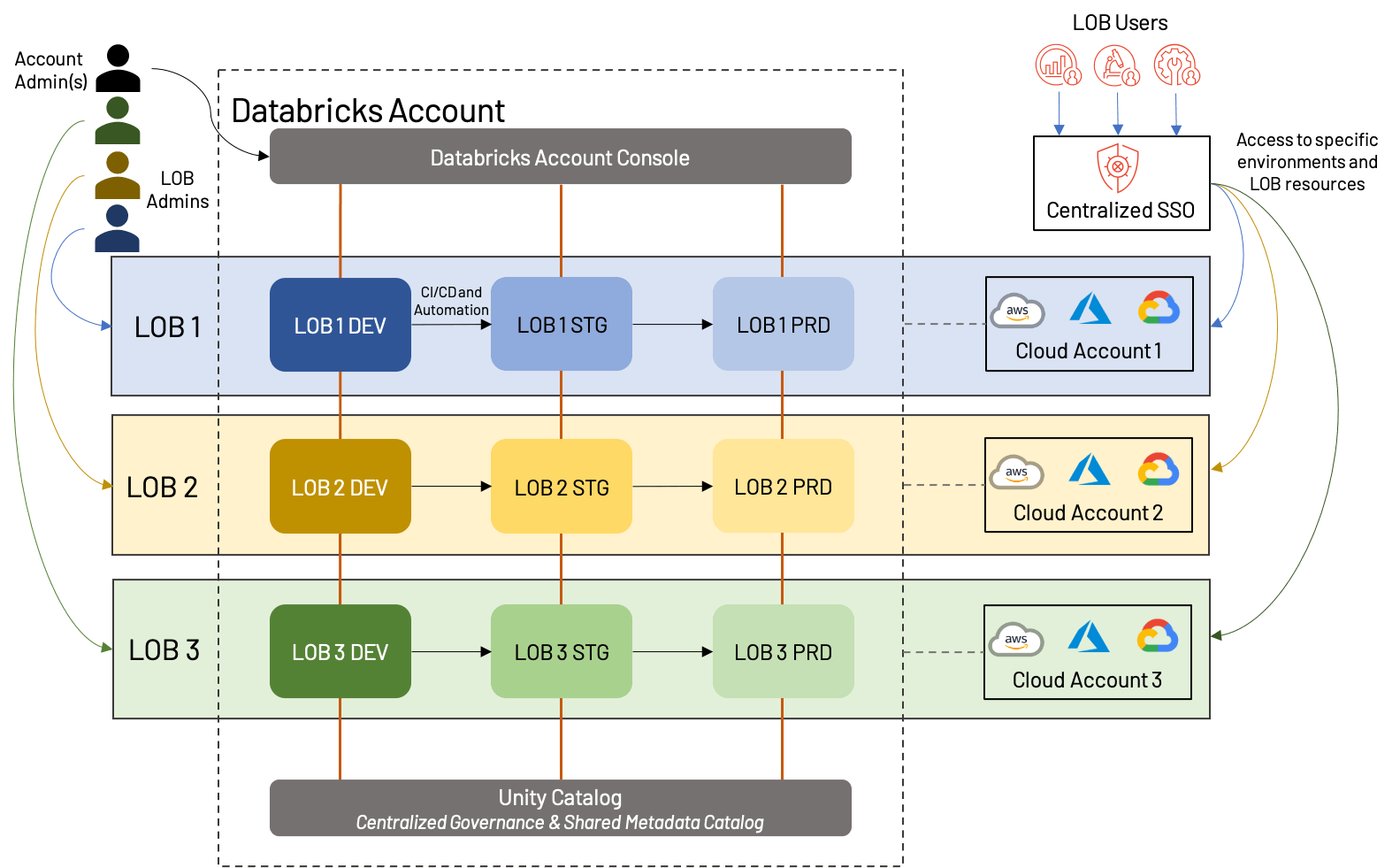
The above diagram exhibits one potential method that LOB-based workspace could be structured; on this case, every LOB has a separate cloud account with one workspace in every surroundings (dev/stg/prd) and likewise has a devoted admin. Importantly, all of those workspaces fall underneath the identical Databricks account, and leverage the identical Unity Catalog. Some variations would come with sharing cloud accounts (and doubtlessly underlying assets resembling VPCs and cloud providers), utilizing a separate dev/stg/prd cloud account, or creating separate exterior metastores for every LOB. These are all affordable approaches that rely closely on enterprise wants.
Total, there are a number of advantages, in addition to a couple of drawbacks to the LOB strategy:
+Belongings for every LOB could be remoted, each from a cloud perspective and from a workspace perspective; this makes for easy reporting/value evaluation, in addition to a much less cluttered workspace.
+Clear division of customers and roles improves the general governance of the Lakehouse, and reduces general threat.
+Automation of promotion between environments creates an environment friendly and low-overhead course of.
–Up-front planning is required to make sure that cross-LOB processes are standardized, and that the general Databricks account is not going to hit platform limits.
–Automation and administrative processes require specialists to arrange and keep.
As greatest practices, we advocate the next to these constructing LOB-based Lakehouses:
- Make use of a least-privilege entry mannequin utilizing fine-grained entry management for customers and environments; typically, only a few customers ought to have manufacturing entry, and interactions with this surroundings needs to be automated and extremely managed. Seize these customers and teams in your identification supplier and sync them to the Lakehouse.
- Perceive and plan for each cloud supplier and Databricks platform limits; these embrace, for instance, the variety of workspaces, API charge limiting on ADLS, throttling on Kinesis streams, and so forth.
- Use a standardized metastore/catalog with robust entry controls wherever doable; this permits for re-use of belongings with out compromising isolation. Unity Catalog permits for fine-grained controls over tables and workspace belongings, which incorporates objects resembling MLflow experiments.
- Leverage information sharing wherever doable to securely share information between LOBs without having to duplicate effort.
Information product isolation
What will we do when LOBs must collaborate cross-functionally, or when a easy dev/stg/prd mannequin doesn’t match the use circumstances of our LOB? We are able to shed a number of the formality of a strict LOB-based Lakehouse construction and embrace a barely extra fashionable strategy; we name this workspace isolation by Information Product. The idea is that as a substitute of isolating strictly by LOB, we isolate as a substitute by top-level tasks, giving every a manufacturing surroundings. We additionally combine in shared growth environments to keep away from workspace proliferation and make reuse of belongings easier.
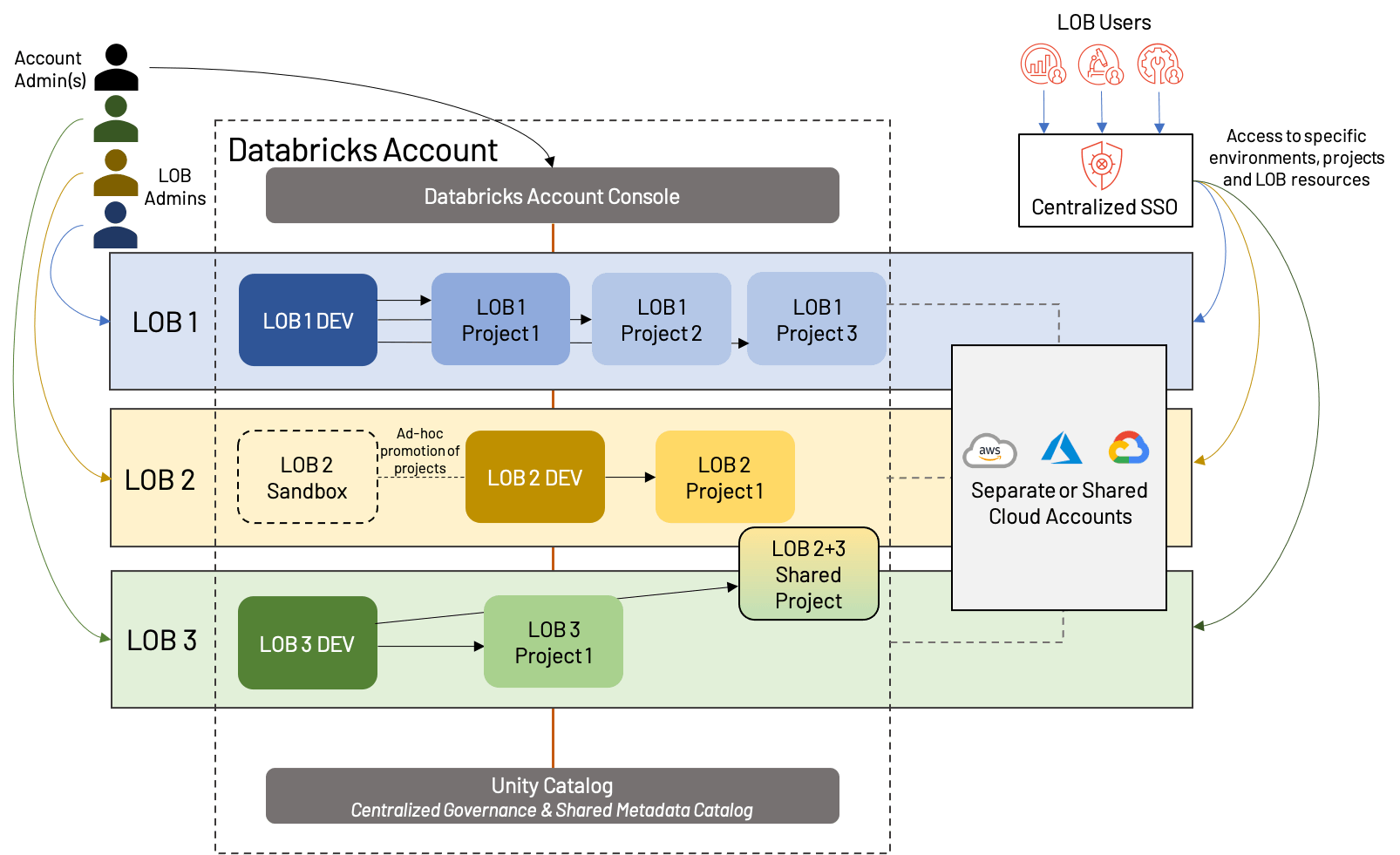
At first look, this seems much like the LOB-based isolation from above, however there are a couple of vital distinctions:
- A shared dev workspace, with separate workspaces for every top-level challenge (which implies every LOB might have a unique variety of workspaces general)
- The presence of sandbox workspaces, that are particular to an LOB, and supply extra freedom and fewer automation than conventional Dev workspaces
- Sharing of assets and/or workspaces; that is additionally doable in LOB-based architectures, however is commonly sophisticated by extra inflexible separation
This strategy shares most of the identical strengths and weaknesses as LOB-based isolation, however gives extra flexibility and emphasizes the worth of tasks within the fashionable Lakehouse. Increasingly more, we see this turning into the “gold commonplace” of workspace group, corresponding with the motion of know-how from primarily a cost-driver to a price generator. As all the time, enterprise wants might drive slight deviations from this pattern structure, resembling devoted dev/stg/prd for significantly massive tasks, cross-LOB tasks, roughly segregation of cloud assets, and so forth. Whatever the precise construction, we propose the next greatest practices:
- Share information and assets at any time when doable; though segregation of infrastructure and workspaces is helpful for governance and monitoring, proliferation of assets rapidly turns into a burden. Cautious evaluation forward of time will assist to determine areas of re-use.
- Even when not sharing extensively between tasks, use a shared metastore resembling Unity Catalog, and shared code-bases (through, i.e., Repos) the place doable.
- Use Terraform (or comparable instruments) to automate the method of making, managing and deleting workspaces and cloud infrastructure.
- Present flexibility to customers through sandbox environments, however be certain that these have acceptable guard rails set as much as restrict cluster sizes, information entry, and so forth.
Abstract
To completely leverage all the advantages of the Lakehouse and help future development and manageability, care needs to be taken to plan workspace structure. Different related artifacts that have to be thought-about throughout this design embrace a centralized mannequin registry, codebase, and catalog to help collaboration with out compromising safety. To summarize a number of the greatest practices highlighted all through this text, our key takeaways are listed beneath:
Finest Observe #1: Reduce the variety of top-level accounts (each on the cloud supplier and Databricks stage) the place doable, and create a workspace solely when separation is important for compliance, isolation, or geographical constraints. When unsure, preserve it easy!
Finest Observe #2: Determine on an isolation technique that can present you long-term flexibility with out undue complexity. Be real looking about your wants and implement strict pointers earlier than starting to onramp workloads to your Lakehouse; in different phrases, measure twice, reduce as soon as!
Finest Observe #3: Automate your cloud processes. This ranges each facet of your infrastructure (lots of which will probably be lined in following blogs!), together with SSO/SCIM, Infrastructure-as-Code with a software resembling Terraform, CI/CD pipelines and Repos, cloud backup, and monitoring (utilizing each cloud-native and third-party instruments).
Finest Observe #4: Take into account establishing a COE crew for central governance of an enterprise-wide technique, the place repeatable facets of an information and machine studying pipeline is templatized and automatic in order that completely different information groups can use self-service capabilities with sufficient guardrails in place. The COE crew is commonly a light-weight however important hub for information groups and will view itself as an enabler- sustaining documentation, SOPs, how-tos and FAQs to coach different customers.
Finest Observe #5: The Lakehouse offers a stage of governance that the Information Lake doesn’t; take benefit! Assess your compliance and governance wants as one of many first steps of building your Lakehouse, and leverage the options that Databricks offers to verify threat is minimized. This consists of audit log supply, HIPAA and PCI (the place relevant), correct exfiltration controls, use of ACLs and consumer controls, and common assessment of all the above.
We’ll be offering extra Admin greatest apply blogs within the close to future, on subjects from Information Governance to Consumer Administration. Within the meantime, attain out to your Databricks account crew with questions on workspace administration, or if you happen to’d wish to be taught extra about greatest practices on the Databricks Lakehouse Platform!
[ad_2]